Kaynak Metin: https://tinyurl.com/4pht7utw
ChatGPT'nin yüzeysel olarak bile insan eliyle yazılmış metinlere benzeyen bir metni otomatik olarak oluşturabilmesi dikkat çekici ve beklenmedik bir şey. Fakat bunu nasıl yapıyor? Neden işe yarıyor? Buradaki amacım ChatGPT'nin içinde neler olup bittiğinin kabaca bir taslağını vermek ve ardından anlamlı metin olarak kabul edebileceğimiz şeyleri üretmede neden bu kadar başarılı olduğunu araştırmak. Başlangıçta, neler olup bittiğine dair büyük resme odaklanacağımı ve bazı mühendislik detaylarından bahsedecek olsam da, bunlara derinlemesine girmeyeceğimi söylemeliyim. (Ayrıca söyleyeceklerimin özü ChatGPT için olduğu kadar diğer mevcut "büyük dil modelleri" [LLM'ler] için de geçerlidir).
*LLM= Büyük Dil Modeli
Açıklanması gereken ilk şey, ChatGPT'nin her zaman temelde yapmaya çalıştığı şeyin, şu ana kadar elde ettiği metnin "makul bir devamını" üretmek olduğudur; burada "makul" ile "insanların milyarlarca web sayfasında vb. yazdıklarını gördükten sonra birinin yazmasını bekleyebileceğimiz şeyi" kastediyoruz.
Diyelim ki elimizde "Yapay zekanın en iyi yanı yapabilme kabiliyetidir" metni var. İnsanların yazdığı milyarlarca sayfalık metni (örneğin web'de ve dijitalleştirilmiş kitaplarda) taradığınızı ve bu metnin tüm örneklerini bulduğunuzu ve ardından hangi kelimenin ne kadar zaman sonra geldiğini gördüğünüzü hayal edin. ChatGPT etkili bir şekilde buna benzer bir şey yapar, ancak (açıklayacağım gibi) gerçek metne bakmaz; belirli bir anlamda "anlam bakımından eşleşen" şeyleri arar. Ancak sonuçta, "olasılıklar" ile birlikte takip edebilecek kelimelerin sıralı bir listesini üretir:

Dikkat çekici olan şey ise, ChatGPT bir deneme yazmak gibi bir şey yaptığında, aslında yaptığı şey sadece tekrar tekrar "şu ana kadarki metin göz önüne alındığında, bir sonraki kelime ne olmalı?" diye sormak ve her seferinde bir kelime eklemektir. (Daha doğrusu, açıklayacağım gibi, bir kelimenin sadece bir parçası olabilen bir "belirteç" ekliyor, bu yüzden bazen "yeni kelimeler uydurabiliyor").
Peki, tamam, her adımda olasılıklarla birlikte bir kelime listesi alıyor. Ancak yazmakta olduğu makaleye (ya da her neyse) eklemek için hangisini seçmelidir? Birisi bunun "en yüksek dereceli" kelime olması gerektiğini düşünebilir (yani en yüksek "olasılığın" atandığı kelime). Ancak burada işin içine biraz voodoo girmeye başlar. Çünkü bir nedenden dolayı - belki bir gün bilimsel bir anlayışa sahip olacağız - her zaman en yüksek sıralamaya sahip kelimeyi seçersek, genellikle "yaratıcılık göstermeyen" (ve hatta bazen kelimesi kelimesine tekrar eden) çok "düz" bir kompozisyon elde ederiz. Ancak bazen (rastgele) daha düşük sıralı kelimeleri seçersek, "daha ilginç" bir kompozisyon elde ederiz.
Burada rastgelelik olduğu gerçeği, aynı soruyu birden fazla kez kullanırsak, her seferinde farklı denemeler alabileceğimiz anlamına gelir. Ve voodoo fikrine uygun olarak, daha düşük sıralı kelimelerin ne sıklıkla kullanılacağını belirleyen belirli bir "sıcaklık" parametresi vardır ve kompozisyon üretimi için 0,8'lik bir "sıcaklık" en iyisi gibi görünmektedir. (Burada herhangi bir "teori" kullanılmadığını vurgulamakta fayda var; bu sadece pratikte neyin işe yaradığı ile ilgili bir mesele. Ve örneğin "sıcaklık" kavramı, istatistiksel fizikten aşina olduğumuz üstel dağılımlar kullanıldığı için var, ancak "fiziksel" bir bağlantı yok - en azından bildiğimiz kadarıyla).
Devam etmeden önce, açıklama amacıyla çoğunlukla ChatGPT'deki tam sistemi kullanmayacağımı açıklamalıyım; bunun yerine genellikle standart bir masaüstü bilgisayarda çalışabilecek kadar küçük olması gibi güzel bir özelliği olan daha basit bir GPT-2 sistemi ile çalışacağım. Ve böylece gösterdiğim her şey için bilgisayarınızda hemen çalıştırabileceğiniz açık Wolfram Dili kodunu ekleyebileceğim. (Buradaki herhangi bir resme tıklayarak arkasındaki kodu kopyalayabilirsiniz).
Örneğin, yukarıdaki olasılıklar tablosunu nasıl elde edeceğiniz aşağıda açıklanmıştır. İlk olarak, altta yatan "dil modeli" sinir ağını almamız gerekiyor:

Daha sonra bu sinir ağının içine bakacağız ve nasıl çalıştığından bahsedeceğiz. Ancak şimdilik bu "ağ modelini" bir kara kutu olarak şimdiye kadarki metnimize uygulayabilir ve modelin takip etmesi gerektiğini söylediği olasılığa göre ilk 5 kelimeyi sorabiliriz:

Bu sonucu alır ve onu açık bir şekilde biçimlendirilmiş bir "veri kümesi" haline getirir:


Daha uzun süre devam ederse ne olur? Bu durumda ("sıfır sıcaklık") ortaya çıkan şey kısa sürede oldukça karışık ve tekrarlayıcı hale gelir:

Peki ya her zaman "en iyi" kelimeyi seçmek yerine bazen rastgele "en iyi olmayan" kelimeleri seçerse ("sıcaklık" 0.8'e karşılık gelen "rastgelelik" ile)? Yine bir metin oluşturulabilir:

Bunu her yaptığınızda, farklı rastgele seçimler yapılacak ve metin farklı olacaktır - bu 5 örnekte olduğu gibi:

İlk adımda bile seçilebilecek çok sayıda olası "sonraki kelime" olduğunu (0,8 sıcaklıkta), ancak bunların olasılıklarının oldukça hızlı bir şekilde düştüğünü belirtmek gerekir (ve evet, bu log-log grafiğindeki düz çizgi, dilin genel istatistiklerinin çok karakteristik bir özelliği olan n-1 "güç yasası" düşüşüne karşılık gelir):

Öyleyse biri daha uzun sürerse ne olur? İşte rastgele bir örnek. En üstteki (sıfır sıcaklık) durumdan daha iyi, ancak yine de en iyi ihtimalle biraz garip:

Yapay zeka ile ilgili en iyi şey, paniğe kapılıp görmezden gelmek yerine etrafımızdaki dünyayı görebilme ve anlamlandırabilme yeteneğidir. Bu, YZ'nin "işini yapması" ya da YZ'nin "sıradanlaşması" olarak bilinir. Gerçekten de, sonsuz sayıda adım atmak, diğer sistemlerle entegre edilebilen bir makine geliştirmek veya gerçekten bir makine olan bir sistemi kontrol etmek, yapay zekanın en temel süreçlerinden biridir. İnsan-makine etkileşiminin yanı sıra, YZ yaratıcılığın da büyük bir parçasıydı.
Bu, en basit GPT-2 modeliyle (2019'dan itibaren) yapıldı. Daha yeni ve daha büyük GPT-3 modelleri ile sonuçlar daha iyi. İşte aynı "komut istemi" ile, ancak en büyük GPT-3 modeli ile üretilen en üst kelime (sıfır sıcaklık) metni:

Yapay zeka ile ilgili en iyi şey, süreçleri otomatikleştirme ve hızlı ve doğru kararlar alma yeteneğidir. Yapay zeka, veri girişi gibi sıradan görevleri otomatikleştirmek için kullanılabileceği gibi, müşteri davranışını tahmin etmek veya büyük veri kümelerini analiz etmek gibi karmaşık kararlar almak için de kullanılabilir. YZ, müşteri sorularına hızlı ve doğru bir şekilde yanıt verebileceğinden müşteri hizmetlerini iyileştirmek için de kullanılabilir. YZ ayrıca tıbbi teşhislerin doğruluğunu artırmak ve ilaç keşif sürecini otomatikleştirmek için de kullanılabilir.
İşte "0,8 sıcaklıkta" rastgele bir örnek:

Yapay zeka ile ilgili en iyi şey, zaman içinde öğrenme ve gelişme yeteneğidir, bu da performansını sürekli olarak iyileştirmesine ve görevlerde daha verimli olmasına olanak tanır. Yapay zeka, sıradan görevleri otomatikleştirmek için de kullanılabilir ve insanların daha önemli görevlere odaklanmasına olanak tanır. YZ ayrıca karar vermek ve aksi takdirde insanların anlaması imkansız olacak içgörüler sağlamak için de kullanılabilir.
Olasılıklar Nereden Geliyor?
Yani ChatGPT bir sonraki kelimeyi her zaman olasılıklara göre seçer. Fakat bu olasılıklar nereden geliyor? Daha basit bir problemle başlayalım. Bir seferde bir harf (kelime yerine) İngilizce metin oluşturmayı düşünelim. Her harf için olasılığın ne olması gerektiğini nasıl hesaplayabiliriz?
Yapabileceğimiz en basit şey, bir İngilizce metin örneği almak ve farklı harflerin bu metinde ne sıklıkla geçtiğini hesaplamaktır. Örneğin bu, Vikipedi'deki "kediler" maddesindeki harfleri sayar:

Aynı şeyi "köpekler" için yaparsa:

Sonuçlar benzerdir, ancak aynı değildir ("o" şüphesiz "dogs" maddesinde daha yaygındır, çünkü sonuçta "dog" kelimesinin kendisinde görülür). Yine de, yeterince büyük bir İngilizce metin örneği alırsak, sonunda en azından oldukça tutarlı sonuçlar elde etmeyi bekleyebiliriz:

İşte bu olasılıklarla bir harf dizisi oluşturursak ne elde edeceğimizin bir örneği:
"Kelime uzunluklarının" dağılımını İngilizcedekiyle uyumlu olmaya zorlayarak "kelime" yapma konusunda biraz daha iyi bir iş çıkarabiliriz:
Burada herhangi bir "gerçek kelime" elde edemedik, ancak sonuçlar biraz daha iyi görünüyor. Yine de daha ileri gitmek için her harfi ayrı ayrı rastgele seçmekten daha fazlasını yapmamız gerekiyor. Örneğin, elimizde bir "q" harfi varsa, bir sonraki harfin temelde "u" olması gerektiğini biliyoruz.
İşte harflerin kendi başlarına olasılıklarının bir grafiği:

Ve işte tipik İngilizce metindeki harf çiftlerinin (" 2-gram ") olasılıklarını gösteren bir çizim. Olası ilk harfler sayfa boyunca, ikinci harfler ise sayfanın aşağısında gösterilmiştir:


Ancak şimdi - aşağı yukarı ChatGPT'nin yaptığı gibi - harflerle değil, tüm kelimelerle uğraştığımızı varsayalım. İngilizce'de yaygın olarak kullanılan yaklaşık 40.000 kelime vardır. Büyük bir İngilizce metin külliyatına bakarak (diyelim ki birkaç milyon kitap, toplamda birkaç yüz milyar kelime), her bir kelimenin ne kadar yaygın olduğuna dair bir tahmin elde edebiliriz. Bunu kullanarak, her bir sözcüğün bağımsız olarak rastgele seçildiği "cümleler" oluşturmaya başlayabiliriz, bu cümleler derlemde görünme olasılığı ile aynıdır. İşte elde ettiklerimizin bir örneği:

Şaşırtıcı olmayan bir şekilde, bu anlamsız. Peki nasıl daha iyisini yapabiliriz? Tıpkı harflerde olduğu gibi, sadece tek kelimeler için olasılıkları değil, çiftler veya daha uzun kelime n-gramları için olasılıkları da dikkate almaya başlayabiliriz. Bunu çiftler için yaptığımızda, her durumda "kedi" kelimesinden başlayarak elde ettiğimiz 5 örneği burada bulabilirsiniz:

kedi nakliye çeşitliliği ile acil yardım yapılabilir
Kitap çevirme için kedi tasarımına genel olarak karar verildi
elektrik kamu arasında birleşen çevreyi kontrol altına almak için güvenlikte kedi
bir onay prosedüründe baştan sona kedi ve ikisi zor müzikti
Teoride kedi zaten bir temsilden önce bir
Biraz daha "mantıklı" görünmeye başladı. Ve yeterince uzun n-gramlar kullanabilseydik, temelde "bir ChatGPT elde edeceğimizi" hayal edebiliriz - "doğru genel deneme olasılıkları" ile deneme uzunluğunda kelime dizileri üretecek bir şey elde etmek anlamında. Ancak sorun şu: bu olasılıkları çıkarabilmek için şimdiye kadar yazılmış yeterince İngilizce metin yok.
İnternette yapılan bir taramada birkaç yüz milyar kelime bulunabilir; dijital ortama aktarılmış kitaplarda ise bir yüz milyar kelime daha olabilir. Ancak 40.000 ortak kelimeyle bile olası 2-gramların sayısı zaten 1,6 milyar ve olası 3-gramların sayısı 60 trilyondur. Yani tüm bunlar için bile olasılıkları mevcut metinden tahmin etmemizin bir yolu yok. Ve 20 kelimelik "deneme parçalarına" ulaştığımızda, olasılıkların sayısı evrendeki parçacıkların sayısından daha fazladır, bu yüzden bir anlamda hepsi asla yazılamaz.
Peki ne yapabiliriz? Ana fikir, baktığımız metin külliyatında bu dizileri açıkça hiç görmemiş olsak bile, dizilerin hangi olasılıklarla ortaya çıkması gerektiğini tahmin etmemizi sağlayan bir model oluşturmaktır. ChatGPT'nin özünde, bu olasılıkları tahmin etmek için iyi bir iş çıkarmak üzere oluşturulmuş bir "büyük dil modeli" (LLM) vardır.
Model Nedir?
Diyelim ki (Galileo'nun 1500'lerin sonunda yaptığı gibi) Pisa Kulesi'nin her katından atılan bir top güllesinin yere ne kadar sürede çarpacağını bilmek istiyorsunuz. Her durumda ölçebilir ve sonuçları bir tablo haline getirebilirsiniz. Ya da teorik bilimin özü olan şeyi yapabilirsiniz: her vakayı ölçüp hatırlamak yerine cevabı hesaplamak için bir tür prosedür veren bir model oluşturabilirsiniz.
Top güllesinin çeşitli katlardan ne kadar sürede düştüğüne dair (biraz idealize edilmiş) verilere sahip olduğumuzu düşünelim:

Hakkında açıkça veri sahibi olmadığımız bir zeminden düşmenin ne kadar süreceğini nasıl hesaplarız? Bu özel durumda, bunu çözmek için bilinen fizik yasalarını kullanabiliriz. Öte yandan diyelim ki elimizde sadece veriler var ve bu verilerin altında yatan yasaları bilmiyoruz. O zaman matematiksel bir tahminde bulunabiliriz, örneğin belki de model olarak düz bir çizgi kullanmalıyız:

Farklı düz çizgiler seçebiliriz. Ancak bu, bize verilen verilere ortalama olarak en yakın olanıdır. Ve bu düz çizgiden herhangi bir zemin için düşme süresini tahmin edebiliriz.
Burada düz bir çizgi kullanmayı deneyeceğimizi nereden bildik? Bir seviyede bilmiyorduk. Bu sadece matematiksel olarak basit bir şey ve ölçtüğümüz pek çok verinin matematiksel olarak basit şeylerle iyi uyum sağladığı gerçeğine alışkınız. Matematiksel olarak daha karmaşık bir şey deneyebiliriz - a + b x + c (x^2) diyebiliriz - ve bu durumda daha iyisini yaparız:

Yine de işler oldukça yanlış gidebilir. Mesela a + b/x + c sin(x) ile yapabileceğimizin en iyisi bu:
Hiçbir zaman "modelsiz bir model" olmadığını anlamakta fayda vardır. Kullandığınız herhangi bir modelin altında yatan belirli bir yapı vardır - daha sonra verilerinize uyması için belirli bir dizi "çevirebileceğiniz düğmeler" (yani ayarlayabileceğiniz parametreler) vardır. ChatGPT söz konusu olduğunda, bu tür pek çok "düğme" kullanılır - aslında 175 milyar tane.
Ancak dikkat çekici olan, ChatGPT'nin altında yatan yapının - "sadece" bu kadar çok parametre ile- bize makul uzunlukta metin parçaları vermek için sonraki kelime olasılıklarını "yeterince iyi" hesaplayan bir model oluşturmak için yeterli olmasıdır.
İnsan Benzeri Görevler için Modeller
Yukarıda verdiğimiz örnek, esasen basit fizikten gelen sayısal veriler için bir model oluşturmayı içeriyor - birkaç yüzyıldır "basit matematiğin geçerli olduğunu" biliyoruz. Ancak ChatGPT için insan beyni tarafından üretilen türden bir insan dili metni modeli oluşturmamız gerekiyor. Böyle bir şey için elimizde (en azından henüz) "basit matematik" gibi bir şey yok. Peki bunun bir modeli nasıl olabilir?
Dil hakkında konuşmadan önce, insan benzeri başka bir görevden bahsedelim: görüntüleri tanımak. Bunun basit bir örneği olarak, rakamların görüntülerini ele alalım(bu klasik bir makine öğrenimi örneğidir):

Yapabileceğimiz şeylerden biri, her rakam için bir grup örnek görüntü elde etmektir:

O zaman bize girdi olarak verilen bir görüntünün belirli bir rakama karşılık gelip gelmediğini anlamak için elimizdeki örneklerle piksel piksel açık bir karşılaştırma yapabiliriz. Ancak insanlar olarak kesinlikle daha iyi bir şey yapıyor gibi görünüyoruz - çünkü örneğin el yazısıyla yazılmış olsalar ve her türlü değişiklik ve bozulmaya sahip olsalar bile rakamları tanıyabiliyoruz:

Yukarıdaki sayısal verilerimiz için bir model oluşturduğumuzda, bize verilen sayısal bir x değerini alıp belirli a ve b için a + b x'i hesaplayabildik. Peki, buradaki her pikselin gri düzey değerini xi değişkeni olarak ele alırsak, tüm bu değişkenlerin - değerlendirildiğinde - görüntünün hangi basamakta olduğunu söyleyen bir fonksiyonu var mı? Böyle bir fonksiyon oluşturmanın mümkün olduğu ortaya çıktı. Şaşırtıcı olmayan bir şekilde, bu pek de basit değil. Ve tipik bir örnek belki de yarım milyon matematiksel işlem içerebilir.
Ancak sonuç olarak, bir görüntünün piksel değerleri koleksiyonunu bu işleve beslersek, hangi rakamın görüntüsüne sahip olduğumuzu belirten sayı ortaya çıkacaktır. Daha sonra, böyle bir fonksiyonun nasıl oluşturulabileceğinden ve sinir ağları fikrinden bahsedeceğiz. Ancak şimdilik bu fonksiyonu kara kutu olarak ele alalım; örneğin el yazısıyla yazılmış rakamların görüntülerini (piksel değerleri dizileri olarak) girelim ve bunların karşılık geldiği sayıları elde edelim:

Ama burada gerçekten neler oluyor? Diyelim ki bir rakamı giderek bulanıklaştırıyoruz. Kısa bir süre için fonksiyonumuz onu hala "tanır", burada "2" olarak. Ancak kısa süre sonra "kaybeder" ve "yanlış" sonuç vermeye başlar:

Ama neden bunun "yanlış" sonuç olduğunu söylüyoruz? Bu durumda, bir "2 "yi bulanıklaştırarak tüm görüntüleri elde ettiğimizi biliyoruz. Ancak amacımız insanların görüntüleri tanıma konusunda neler yapabileceğine dair bir model oluşturmaksa, sorulması gereken asıl soru, bir insana bu bulanık görüntülerden biri sunulduğunda, nereden geldiğini bilmeden ne yapacağıdır.
İşlevimizden elde ettiğimiz sonuçlar tipik olarak bir insanın söyleyecekleriyle uyuşuyorsa "iyi bir modelimiz" var demektir. Ve önemsiz olmayan bilimsel gerçek şu ki, bunun gibi bir görüntü tanıma görevi için artık temel olarak bunu yapan fonksiyonları nasıl oluşturacağımızı biliyoruz.
İşe yaradıklarını "matematiksel olarak kanıtlayabilir miyiz"? Şey, hayır. Çünkü bunu yapmak için biz insanların ne yaptığına dair matematiksel bir teoriye sahip olmamız gerekir. "2" görüntüsünü alın ve birkaç pikseli değiştirin. Sadece birkaç pikselin "yerinden oynaması" durumunda görüntüyü hala "2" olarak kabul etmemiz gerektiğini düşünebiliriz. Ama bu ne kadar ileri gitmeli? Bu insanın görsel algısıyla ilgili bir sorudur. Cevap şüphesiz arılar veya ahtapotlar için farklı olacaktır - ve potansiyel olarak varsayılan uzaylılar için tamamen farklı olacaktır.
Sinir Ağları
Peki görüntü tanıma gibi görevler için tipik modellerimiz gerçekte nasıl çalışır? En popüler ve başarılı güncel yaklaşım sinir ağlarını kullanır. 1940'larda, bugünkü kullanımlarına oldukça yakın bir biçimde icat edilen sinir ağları, beyinlerin nasıl çalıştığına dair basit idealleştirmeler olarak düşünülebilir.
İnsan beyninde yaklaşık 100 milyar nöron (sinir hücresi) vardır ve bunların her biri saniyede belki bin kez elektriksel darbe üretebilir. Nöronlar karmaşık bir ağ ile birbirine bağlıdır ve her bir nöron, elektrik sinyallerini belki de binlerce başka nörona iletmesini sağlayan ağaç benzeri dallara sahiptir. Ve kaba bir yaklaşımla, herhangi bir nöronun belirli bir anda elektriksel bir darbe üretip üretmediği, diğer nöronlardan aldığı darbelere bağlıdır - farklı bağlantılar farklı "ağırlıklarla" katkıda bulunur.
"Bir görüntü gördüğümüzde" olan şey, görüntüden gelen ışık fotonları gözlerimizin arkasındaki hücrelere ("fotoreseptör") düştüğünde sinir hücrelerinde elektrik sinyalleri üretmeleridir. Bu sinir hücreleri diğer sinir hücrelerine bağlanır ve sonunda sinyaller bir dizi nöron katmanından geçer. Ve bu süreçte görüntüyü "tanırız", sonunda "2 gördüğümüz" düşüncesini "oluştururuz" (ve belki de sonunda "iki" kelimesini yüksek sesle söylemek gibi bir şey yaparız).
Önceki bölümdeki "kara kutu" işlevi, böyle bir sinir ağının "matematikselleştirilmiş" bir versiyonudur. Bunun 11 katmanı vardır (ancak sadece 4 "çekirdek katmanı" vardır):

Bu sinir ağında özellikle "teorik olarak türetilmiş" bir şey yok; sadece 1998'de bir mühendislik eseri olarak inşa edilmiş ve çalıştığı tespit edilmiş bir şey. (Tabii ki bu, beynimizin biyolojik evrim sürecinde üretildiğini söylememizden çok da farklı değil).
Peki, ama bunun gibi bir sinir ağı "şeyleri nasıl tanır"? Anahtar, çekiciler kavramıdır. Elimizde 1'ler ve 2'lerden oluşan el yazısı resimler olduğunu düşünün:

Bir şekilde tüm 1'lerin "bir yere çekilmesini" ve tüm 2'lerin "başka bir yere çekilmesini" istiyoruz. Ya da başka bir deyişle, eğer bir görüntü bir şekilde "1 olmaya 2 olmaktan daha yakınsa", onun "1 yerinde" olmasını isteriz ve bunun tersi de geçerlidir.
Basit bir benzetme olarak, diyelim ki düzlemde noktalarla gösterilen belirli konumlarımız var (gerçek hayat ortamında bunlar kahve dükkanlarının konumları olabilir). O zaman düzlemdeki herhangi bir noktadan başlayarak her zaman en yakın noktaya varmak istediğimizi hayal edebiliriz (yani her zaman en yakın kafeye gideriz). Bunu, düzlemi idealize edilmiş "su havzaları" ile ayrılmış bölgelere ("çekici havzalar") bölerek temsil edebiliriz:

Bunu, belirli bir görüntünün "en çok hangi rakama benzediğini" belirlemek gibi bir şey yapmadığımız bir tür "tanıma görevi" uygulamak olarak düşünebiliriz - daha ziyade, oldukça doğrudan, belirli bir noktanın hangi noktaya en yakın olduğunu görüyoruz. (Burada gösterdiğimiz "Voronoi diyagramı" düzeni, noktaları 2 boyutlu Öklid uzayında ayırıyor; rakam tanıma görevi de çok benzer bir şey yapıyor gibi düşünülebilir - ancak her görüntüdeki tüm piksellerin gri seviyelerinden oluşan 784 boyutlu bir uzayda).
Peki bir sinir ağının "tanıma görevi yapmasını" nasıl sağlarız? Bu çok basit durumu ele alalım:

Amacımız {x,y} pozisyonuna karşılık gelen bir "girdi" almak ve daha sonra bunu üç noktadan hangisine en yakınsa o şekilde "tanımak". Yahut başka bir deyişle, sinir ağının {x,y} gibi bir fonksiyonu hesaplamasını istiyoruz:

Peki bunu bir sinir ağı ile nasıl yaparız? Nihayetinde bir sinir ağı, genellikle katmanlar halinde düzenlenmiş idealize edilmiş "nöronların" bağlantılı bir koleksiyonudur ve basit bir örneği vardır:


Geleneksel (biyolojik olarak esinlenilmiş) kurulumda her nöron, bir önceki katmandaki nöronlardan etkin bir şekilde belirli bir "gelen bağlantılar" kümesine sahiptir ve her bağlantıya belirli bir "ağırlık" (pozitif veya negatif bir sayı olabilir) atanır. Belirli bir nöronun değeri, "önceki nöronların" değerlerinin karşılık gelen ağırlıklarla çarpılması, ardından bunların toplanması ve bir sabitin eklenmesi ve son olarak bir "eşikleme" (veya "aktivasyon") fonksiyonunun uygulanmasıyla belirlenir. Matematiksel terimlerle, eğer bir nöronun x = {x1, x2 ...} girdileri varsa, o zaman f[w . x + b]'yi hesaplarız; burada w ağırlıkları ve b sabiti genellikle ağdaki her nöron için farklı seçilir; f fonksiyonu genellikle aynıdır.
w . x + b'nin hesaplanması sadece bir matris çarpma ve toplama işlemidir. "Aktivasyon fonksiyonu" f doğrusal olmama özelliğini ortaya çıkarır (ve sonuçta önemsiz davranışa yol açar). Genellikle çeşitli aktivasyon fonksiyonları kullanılır; burada sadece Ramp (veya ReLU) kullanacağız:

Sinir ağının gerçekleştirmesini istediğimiz her görev için (ya da eşdeğer olarak, değerlendirmesini istediğimiz her genel işlev için) farklı ağırlık seçeneklerimiz olacaktır. (Ve -daha sonra tartışacağımız gibi- bu ağırlıklar normalde istediğimiz çıktıların örneklerinden makine öğrenimi kullanılarak sinir ağının "eğitilmesi" ile belirlenir).
Nihayetinde, her sinir ağı genel bir matematiksel fonksiyona karşılık gelir - her ne kadar yazması karmaşık olsa da. Yukarıdaki örnek için bu şöyle olacaktır:

ChatGPT'nin sinir ağı da bunun gibi bir matematiksel fonksiyona karşılık gelir - ancak milyarlarca terimle etkili bir biçimde.
Fakat bireysel nöronlara geri dönelim. İki girdisi olan (x ve y koordinatlarını temsil eden) bir nöronun çeşitli ağırlık ve sabit seçenekleriyle (ve aktivasyon fonksiyonu olarak Rampa) hesaplayabileceği fonksiyonlara bazı örnekler aşağıda verilmiştir:

Ya yukarıdaki daha büyük ağ ne olacak? İşte hesapladığı şey:

Tam olarak "doğru" değil, ancak yukarıda gösterdiğimiz "en yakın nokta" fonksiyonuna yakın.
Diğer bazı sinir ağlarında ne olduğunu görelim. Her durumda, daha sonra açıklayacağımız gibi, en iyi ağırlık seçimini bulmak için makine öğrenimini kullanıyoruz. Sonra burada bu ağırlıklarla sinir ağının ne hesapladığını gösteriyoruz:

Daha büyük ağlar genellikle hedeflediğimiz fonksiyona yaklaşmada daha başarılıdır. "Her bir çekici havzanın ortasında" genellikle tam olarak istediğimiz cevabı alırız. Ancak sınırlarda - sinir ağının "karar vermekte zorlandığı" yerlerde - işler daha karmaşık olabilir.
Bu basit matematiksel tarzdaki "tanıma görevi" ile "doğru cevabın" ne olduğu açıktır. Ancak el yazısıyla yazılmış rakamları tanıma probleminde durum o kadar net değildir. Ya birisi "2 "yi o kadar kötü yazmışsa ve "7" gibi görünüyorsa? Yine de, bir sinir ağının rakamları nasıl ayırt ettiğini sorabiliriz ve bu bir gösterge verir:

Ağın ayrımlarını nasıl yaptığını "matematiksel olarak" söyleyebilir miyiz? Pek sayılmaz. Sadece "sinir ağı ne yapıyorsa onu yapıyor". Ancak bunun normalde biz insanların yaptığı ayrımlarla oldukça uyumlu olduğu ortaya çıkıyor.
Daha ayrıntılı bir örnek verelim. Diyelim ki elimizde kedi ve köpek resimleri var. Ve bunları ayırt etmek için eğitilmiş bir sinir ağımız var. İşte bazı örnekler üzerinde yapabilecekleri:

Şimdi "doğru cevabın" ne olduğu daha da belirsiz. Kedi kostümü giymiş bir köpeğe ne dersiniz? vs. Kendisine hangi girdi verilirse verilsin, sinir ağı bir cevap üretiyor. Üstelik bunu insanların yapabilecekleriyle makul ölçüde tutarlı bir şekilde yapıyor. Yukarıda da söylediğim gibi, bu "ilk prensiplerden türetebileceğimiz" bir gerçek değil. Sadece, en azından belirli alanlarda, deneysel olarak doğru olduğu tespit edilmiş bir şeydir. Nöral ağların faydalı olmasının temel nedenlerinden biri de bu: bir şekilde "insan benzeri" bir iş yapma biçimini yakalamaları.
Kendinize bir kedi resmi gösterin ve "Bu niye kedi?" diye sorun. Belki de "Şey, sivri kulaklarını görüyorum, vs." demeye başlarsınız. Oysa bu resmi nasıl kedi olarak algıladığınızı açıklamak çok kolay değildir. Bir beyin için "içine girip" bunu nasıl anladığını görmenin (en azından henüz) bir yolu yoktur. Peki ya (yapay) bir sinir ağı için? Bir kedi resmi gösterdiğinizde her bir "nöronun" ne yaptığını görmek kolaydır. Ancak temel bir görselleştirme elde etmek bile genellikle çok zordur.
Yukarıdaki "en yakın nokta" problemi için kullandığımız son ağda 17 nöron vardır. El yazısı rakamları tanımak için kullanılan ağda ise 2190 nöron var. Kedi ve köpekleri tanımak için kullandığımız ağda ise 60.650 nöron var. Normalde 60.650 boyutlu bir uzayı görselleştirmek oldukça zor olurdu. Ancak bu, görüntülerle uğraşmak üzere kurulmuş bir ağ olduğu için, nöron katmanlarının çoğu, baktığı piksel dizileri gibi diziler halinde düzenlenmiştir.
Tipik bir kedi görüntüsünü ele alırsak


10. katmana gelindiğinde neler olup bittiğini yorumlamak zorlaşır:

Genel olarak sinir ağının "belirli özellikleri seçtiğini" (belki sivri kulaklar da bunlar arasındadır) ve bunları görüntünün neye ait olduğunu belirlemek için kullandığını söyleyebiliriz. Ancak bu özellikler "sivri kulaklar" gibi isimlendirdiğimiz özellikler midir? Çoğunlukla değil.
Beyinlerimiz benzer özellikleri mi kullanıyor? Çoğunlukla bilmiyoruz. Burada gösterdiğimiz gibi bir sinir ağının ilk birkaç katmanının, beyinlerdeki görsel işlemenin ilk seviyesi tarafından seçildiğini bildiklerimize benzer görünen görüntülerin yönlerini (nesnelerin kenarları gibi) seçiyor gibi görünmesi dikkate değerdir.
Diyelim ki sinir ağlarında bir "kedi tanıma teorisi" istiyoruz. Şöyle diyebiliriz: "Bakın, bu özel ağ bunu yapıyor" -ve bu bize hemen "ne kadar zor bir problem" olduğu (ve örneğin kaç nöron veya katman gerekebileceği) hakkında bir fikir verir. Ancak en azından şu an itibariyle ağın ne yaptığına dair "anlatısal bir açıklama" yapmanın bir yolu yok. Belki de bunun nedeni gerçekten hesaplama açısından indirgenemez olması ve her adımı açıkça izlemek dışında ne yaptığını bulmanın genel bir yolunun olmamasıdır. Yahut belki de sadece "bilimi çözemediğimiz" ve neler olup bittiğini özetlememizi sağlayan "doğal yasaları" tanımlayamadığımız içindir.
ChatGPT ile dil üretmekten bahsettiğimizde de aynı tür sorunlarla karşılaşacağız. Yine "ne yaptığını özetlemenin" yolları olup olmadığı da net değil. Dilin zenginliği ve ayrıntıları (ve bizim onunla ilgili deneyimlerimiz) resimlerden daha fazla yol almamızı sağlayabilir.
Makine Öğrenimi ve Sinir Ağlarının Eğitimi
Şimdiye kadar belirli görevlerin nasıl yapılacağını "zaten bilen" sinir ağlarından bahsediyorduk. Sinir ağlarını (muhtemelen beyinlerde de) bu kadar kullanışlı yapan şey, sadece prensipte her türlü görevi yapabilmeleri değil, aynı zamanda bu görevleri yapmak için aşamalı olarak "örneklerden eğitilebilmeleridir".
Kedileri köpeklerden ayırmak için bir sinir ağı yaptığımızda, (örneğin) bıyıkları açıkça bulan bir program yazmamız gerekmez; bunun yerine neyin kedi neyin köpek olduğuna dair çok sayıda örnek gösteririz ve ardından ağın bunlardan bunları nasıl ayırt edeceğini "öğrenmesini" sağlarız.
Burada önemli olan nokta, eğitilen ağın kendisine gösterilen belirli örneklerden "genelleme" yapmasıdır. Yukarıda gördüğümüz gibi, mesele sadece ağın kendisine gösterilen örnek bir kedi görüntüsünün belirli piksel desenini tanıması değildir; daha ziyade, sinir ağının bir şekilde görüntüleri bir tür "genel kedilik" olarak düşündüğümüz şey temelinde ayırt etmeyi başarmasıdır.
Sinir ağı eğitimi gerçekte nasıl çalışır? Esasen her zaman yapmaya çalıştığımız şey, sinir ağının verdiğimiz örnekleri başarılı bir şekilde yeniden üretmesini sağlayan ağırlıkları bulmaktır. Ve sonra sinir ağının bu örnekler arasında "makul" bir şekilde "enterpolasyon" (veya "genelleme") yapmasına güveniyoruz.
Yukarıdaki en yakın noktadan daha da basit bir probleme bakalım. Sadece bir sinir ağının fonksiyonu öğrenmesini sağlamaya çalışalım:

Bu görev için, sadece bir girişi ve bir çıkışı olan bir ağa ihtiyacımız olacak:

Hangi ağırlıkları vs. kullanmalıyız? Her olası ağırlık kümesi ile sinir ağı bazı fonksiyonları hesaplayacaktır. Örneğin, rastgele seçilmiş birkaç ağırlık kümesiyle yaptığı şey şudur:

bu durumların hiçbirinde istediğimiz fonksiyonu yeniden üretmeye yaklaşamadığını açıkça görebiliriz. fonksiyonu yeniden üretecek ağırlıkları nasıl bulacağız?
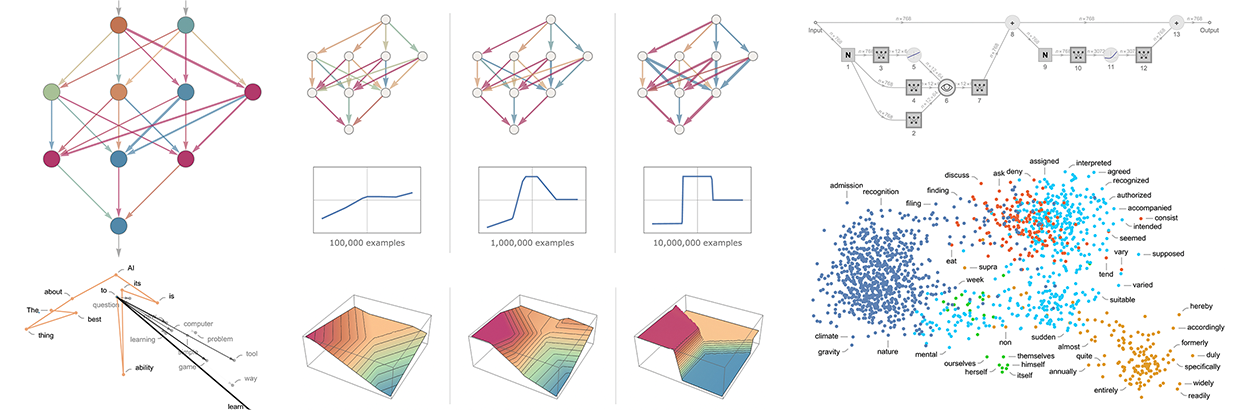
Temel fikir, "öğrenmek" için çok sayıda "girdi → çıktı" örneği sağlamak ve ardından bu örnekleri yeniden üretecek ağırlıkları bulmaya çalışmaktır. İşte bunu giderek daha fazla örnekle yapmanın sonucu:

Bu "eğitimin" her aşamasında ağdaki ağırlıklar kademeli olarak ayarlanır ve sonunda istediğimiz işlevi başarıyla yeniden üreten bir ağ elde ettiğimizi görürüz. Ağırlıkları nasıl ayarlıyoruz? Temel fikir, her aşamada istediğimiz fonksiyonu elde etmekten "ne kadar uzakta olduğumuzu" görmek ve ardından ağırlıkları daha da yaklaşacak şekilde güncellemektir.
"Ne kadar uzakta olduğumuzu" bulmak için genellikle "kayıp fonksiyonu" (veya bazen "maliyet fonksiyonu") olarak adlandırılan şeyi hesaplarız. Burada, elde ettiğimiz değerler ile gerçek değerler arasındaki farkların karelerinin toplamı olan basit bir (L2) kayıp fonksiyonu kullanıyoruz. Eğitim sürecimiz ilerledikçe, kayıp fonksiyonunun giderek azaldığını görüyoruz (farklı görevler için farklı olan belirli bir "öğrenme eğrisini" takip ederek) - ta ki ağın (en azından iyi bir yaklaşımla) istediğimiz fonksiyonu başarıyla yeniden ürettiği bir noktaya ulaşana kadar:

Pekala, açıklanması gereken son önemli parça, kayıp fonksiyonunu azaltmak için ağırlıkların nasıl ayarlandığıdır. Söylediğimiz gibi, kayıp fonksiyonu bize elimizdeki değerler ile gerçek değerler arasında bir "mesafe" verir. "Elimizdeki değerler" her aşamada sinir ağının mevcut versiyonu ve içindeki ağırlıklar tarafından belirlenir. Ama şimdi ağırlıkların değişkenler olduğunu düşünün - örneğin wi. Bu değişkenlerin değerlerini, onlara bağlı olan kaybı en aza indirecek şekilde nasıl ayarlayacağımızı bulmak istiyoruz.
Örneğin, (pratikte kullanılan tipik sinir ağlarının inanılmaz bir şekilde basitleştirilmesiyle) sadece iki ağırlığımız w1 ve w2 olduğunu düşünün. O zaman, w1 ve w2'nin bir fonksiyonu olarak aşağıdaki gibi görünen bir kaybımız olabilir:

Sayısal analiz, bu gibi durumlarda minimum değeri bulmak için çeşitli teknikler sunar. Ancak tipik bir yaklaşım, elimizdeki önceki w1, w2'den itibaren en dik iniş yolunu aşamalı olarak takip etmektir:

Bir dağdan aşağı akan su gibi, garanti edilen tek şey bu prosedürün yüzeyin bazı yerel minimumlarında ("bir dağ gölü") son bulacağıdır; nihai küresel minimuma ulaşmayabilir.
"Ağırlık manzarası" üzerinde en dik iniş yolunu bulmanın mümkün olacağı açık değildir. Ancak hesaplama imdada yetişir. Yukarıda bahsettiğimiz gibi, bir sinir ağını her zaman matematiksel bir fonksiyonu hesaplıyor olarak düşünebiliriz - bu fonksiyon girdilerine ve ağırlıklarına bağlıdır. Ancak şimdi bu ağırlıklara göre farklılaştırmayı düşünün. Kalkülüsün zincir kuralının aslında sinir ağındaki ardışık katmanlar tarafından yapılan işlemleri "çözmemize" izin verdiği ortaya çıkıyor. Sonuç olarak -en azından bazı yerel yaklaşımlarda- sinir ağının işleyişini "tersine çevirebilir" ve çıktı ile ilişkili kaybı en aza indiren ağırlıkları aşamalı olarak bulabiliriz.
Yukarıdaki resim, sadece 2 ağırlığın olduğu gerçekçi olmayan basit bir durumda yapmamız gerekebilecek minimizasyon türünü göstermektedir. Ancak çok daha fazla ağırlıkla bile (ChatGPT 175 milyar ağırlık kullanıyor) en azından belli bir yaklaşım seviyesinde minimizasyon yapmanın mümkün olduğu ortaya çıktı. Ve aslında "derin öğrenme" alanında 2011 yılı civarında gerçekleşen büyük atılım, bir anlamda çok sayıda ağırlık söz konusu olduğunda minimizasyon yapmanın (en azından yaklaşık olarak) oldukça az sayıda ağırlık söz konusu olduğunda olduğundan daha kolay olabileceğinin keşfedilmesiyle ilişkiliydi.
Başka bir deyişle -biraz da sezgisel olarak- sinir ağlarıyla daha karmaşık problemleri çözmek daha basit olanlara göre daha kolay olabilir. Bunun kabaca nedeni, çok sayıda "ağırlık değişkeni" olduğunda, kişiyi minimuma götürebilecek "çok sayıda farklı yöne" sahip yüksek boyutlu bir uzaya sahip olunması gibi görünüyor - oysa daha az değişkenle, "çıkış yönü" olmayan yerel bir minimumda ("dağ gölü") sıkışıp kalmak daha kolay.
Tipik durumlarda, hepsi hemen hemen aynı performansa sahip sinir ağları verecek birçok farklı ağırlık koleksiyonu olduğunu belirtmek gerekir. Ve genellikle pratik sinir ağı eğitiminde, bunlar gibi "farklı ama eşdeğer çözümlere" yol açan çok sayıda rastgele seçim yapılır:


Bunlardan hangisi "doğru"? Söylemenin gerçekten bir yolu yok. Hepsi "gözlemlenen verilerle tutarlı". Ancak hepsi "kutunun dışında" ne yapılacağını "düşünmenin" farklı "doğuştan gelen" yollarına karşılık gelir. Bunlardan bazıları biz insanlara diğerlerinden daha "makul" görünebilir.
Sinir Ağı Eğitiminin Pratiği ve İlmi
Özellikle son on yılda, sinir ağlarını eğitme sanatında pek çok ilerleme kaydedildi. Bu temelde bir sanattır. Bazen -özellikle geçmişe bakıldığında- yapılan bir şey için en azından bir "bilimsel açıklama" parıltısı görülebilir. Çoğunlukla deneme yanılma yoluyla bir şeyler keşfedilmiş, sinir ağlarıyla nasıl çalışılacağına dair önemli bir bilgi birikimi oluşturan fikirler ve püf noktaları eklenmiştir.
Birkaç önemli kısım var. İlk olarak, belirli bir görev için hangi sinir ağı mimarisinin kullanılması gerektiği konusu var. Daha sonra, sinir ağını eğitmek için verilerin nasıl elde edileceği kritik bir konudur. Giderek artan bir şekilde, bir ağı sıfırdan eğitmekle uğraşılmıyor: bunun yerine yeni bir ağ ya doğrudan önceden eğitilmiş başka bir ağı içerebilir ya da en azından kendisi için daha fazla eğitim örneği oluşturmak için bu ağı kullanabilir.
Her özel görev türü için farklı bir sinir ağı mimarisine ihtiyaç duyulacağı düşünülebilir. Ancak bulunan şey, aynı mimarinin görünüşte oldukça farklı görevler için bile sıklıkla işe yaradığıdır. Bu bir düzeyde evrensel hesaplama fikrini (ve benim Hesaplama Eşdeğerliği İlkemi) hatırlatıyor, ancak daha sonra tartışacağım gibi, bunun daha çok sinir ağlarına yaptırmaya çalıştığımız görevlerin "insan benzeri" görevler olduğu ve sinir ağlarının oldukça genel "insan benzeri süreçleri" yakalayabildiği gerçeğinin bir yansıması olduğunu düşünüyorum.
Sinir ağlarının ilk günlerinde, "sinir ağına mümkün olduğunca az şey yaptırmak" gerektiği düşüncesi hakimdi. Örneğin, konuşmayı metne dönüştürürken önce konuşmanın sesini analiz etmek, fonemlere ayırmak vb. gerektiği düşünülüyordu. Ancak, en azından "insan benzeri görevler" için, sinir ağını "uçtan uca problem" üzerinde eğitmeye çalışmanın, gerekli ara özellikleri, kodlamaları vb. kendisi için "keşfetmesine" izin vermenin genellikle daha iyi olduğu anlaşıldı.
Bu, sinir ağlarıyla ilgili hiçbir "yapılandırma fikri" olmadığı anlamına gelmez. Bu nedenle, örneğin, yerel bağlantılara sahip 2 boyutlu nöron dizilerine sahip olmak, en azından görüntüleri işlemenin ilk aşamalarında çok yararlı görünmektedir. "Diziler halinde geriye bakmaya" odaklanan bağlantı modellerine sahip olmak, daha sonra göreceğimiz gibi, örneğin ChatGPT'de insan dili gibi şeylerle başa çıkmada yararlı görünüyor.
Ancak sinir ağlarının önemli bir özelliği, tıpkı genel olarak bilgisayarlar gibi, nihayetinde sadece verilerle uğraşıyor olmalarıdır. Mevcut sinir ağları - sinir ağı eğitimine yönelik mevcut yaklaşımlarla - özellikle sayı dizileriyle ilgilenir. Ancak işlem sırasında bu diziler tamamen yeniden düzenlenebilir ve yeniden şekillendirilebilir. Örnek olarak, yukarıda rakamları tanımlamak için kullandığımız ağ, iki boyutlu "görüntü benzeri" bir diziyle başlar, hızla birçok kanala "kalınlaşır", ancak daha sonra sonuçta farklı olası çıktı rakamlarını temsil eden öğeleri içerecek olan 1 boyutlu bir diziye "yoğunlaşır":

Belirli bir görev için ne kadar büyük bir sinir ağına ihtiyaç duyulacağı nasıl anlaşılabilir? Bu bir çeşit sanattır. Bir seviyede anahtar şey "görevin ne kadar zor olduğunu" bilmektir. Ancak insan benzeri görevler için bunu tahmin etmek genellikle çok zordur. Evet, görevi bilgisayarla çok "mekanik" bir şekilde yapmanın sistematik bir yolu olabilir. Ancak, bir kişinin görevi en azından "insan benzeri bir düzeyde" çok daha kolay bir şekilde yapmasını sağlayan hileler veya kısayollar olarak düşünülebilecek şeyler olup olmadığını bilmek zordur. Belirli bir oyunu "mekanik olarak" oynamak için dev bir oyun ağacını numaralandırmak gerekebilir; ancak "insan düzeyinde oyun" elde etmenin çok daha kolay ("sezgisel") bir yolu olabilir.
Küçük sinir ağları ve basit görevlerle uğraşırken bazen "buradan oraya gidilemeyeceği" açıkça görülebilir. Örneğin, birkaç küçük sinir ağıyla bir önceki bölümdeki görevde yapılabilecek en iyi şey burada görünüyor:

Gördüğümüz şey, ağ çok küçükse, istediğimiz işlevi yeniden üretemediğidir. Ancak belirli bir boyutun üzerinde, en azından yeterince uzun süre ve yeterince örnekle eğitilirse, hiçbir sorunu yoktur. Bu arada, bu resimler bir sinir ağı ilmini göstermektedir: ortada her şeyi daha az sayıda ara nörondan geçmeye zorlayan bir "sıkıştırma" varsa, genellikle daha küçük bir ağ ile kurtulabilirsiniz. (Ayrıca "ara katmansız" ya da "perceptron"(algaç) olarak adlandırılan ağların yalnızca temelde doğrusal işlevleri öğrenebildiğini belirtmek gerekir; ancak bir ara katman bile olduğu anda, en azından yeterli nöron varsa, herhangi bir işlevi keyfi olarak iyi bir şekilde yaklaştırmak prensipte her zaman mümkündür, ancak bunu uygulanabilir bir şekilde eğitilebilir hale getirmek için tipik olarak bir tür düzenleme veya normalleştirme gerekir).
Diyelim ki belli bir sinir ağı mimarisine karar verildi. Şimdi ağı eğitmek için veri elde etme sorunu var. Sinir ağları ve genel olarak makine öğrenimi ile ilgili pratik zorlukların çoğu, gerekli eğitim verilerinin elde edilmesi veya hazırlanmasına odaklanır. Birçok durumda ("denetimli öğrenme") girdilerin ve onlardan beklenen çıktıların açık örneklerini elde etmek gerekir. Bu nedenle, örneğin, içinde ne olduğuna veya başka bir özelliğe göre etiketlenmiş görüntüler istenebilir. Ve belki de etiketleme işlemini açıkça -genellikle büyük bir çabayla- yapmak gerekecektir. Ancak çoğu zaman halihazırda yapılmış olan bir şeyi sırtlamak ya da bir tür vekil olarak kullanmak mümkün olabilir. Örneğin, web'deki resimler için sağlanan alt etiketler kullanılabilir. Ya da farklı bir alanda, videolar için oluşturulmuş altyazılar kullanılabilir. Ya da dil çevirisi eğitimi için web sayfalarının ya da farklı dillerde var olan diğer belgelerin paralel versiyonları kullanılabilir.
Bir sinir ağını belirli bir görev için eğitmek için ne kadar veri göstermeniz gerekir? Yine, ilk prensiplerden yola çıkarak bunu tahmin etmek zordur. Başka bir ağda zaten öğrenilmiş olan önemli özelliklerin listeleri gibi şeyleri "aktarmak" için "transfer öğrenme" kullanılarak gereksinimler kesinlikle önemli ölçüde azaltılabilir. genellikle sinir ağlarının iyi eğitilmesi için "çok sayıda örnek görmesi" gerekir. En azından bazı görevler için, örneklerin inanılmaz derecede tekrarlayıcı olabileceği sinir ağı ilminin önemli bir parçasıdır. Gerçekten de bir sinir ağına sahip olduğu tüm örnekleri tekrar tekrar göstermek standart bir stratejidir. Bu "eğitim turlarının" (veya "epokların") her birinde sinir ağı en azından biraz farklı bir durumda olacaktır ve bir şekilde belirli bir örneği "hatırlatmak", "o örneği hatırlamasını" sağlamak için yararlıdır. (Belki de bu, insanların ezberlemesinde tekrarın faydasına benzer bir durumdur).
Çoğu zaman sadece aynı örneği defalarca tekrarlamak yeterli değildir. Sinir ağına örneğin varyasyonlarını da göstermek gerekir. Bu "veri artırma" varyasyonlarının faydalı olması için sofistike olması gerekmediği sinir ağı ilminin bir özelliğidir. Görüntüleri temel görüntü işleme yöntemleriyle hafifçe değiştirmek, onları sinir ağı eğitimi için esasen "yeni kadar iyi" hale getirebilir. Benzer şekilde, sürücüsüz arabaları eğitmek için gerçek video vb. kaynaklar tükendiğinde, gerçek dünya sahnelerinin tüm ayrıntıları olmadan, video oyunu benzeri bir ortamda simülasyonlar çalıştırarak veri elde edilebilir.
ChatGPT gibi bir şeye ne dersiniz? "Denetimsiz öğrenme" yapabilmesi gibi güzel bir özelliği var, bu da onu eğitmek için örnekler almayı çok daha kolay hale getiriyor. ChatGPT'nin temel görevinin kendisine verilen bir metin parçasını nasıl devam ettireceğini bulmak olduğunu hatırlayın. Dolayısıyla, "eğitim örnekleri" elde etmek için tek yapılması gereken bir metin parçası almak ve sonunu maskelemek ve daha sonra bunu "eğitilecek girdi" olarak kullanmaktır - "çıktı" tam, maskelenmemiş metin parçasıdır. Bunu daha sonra tartışacağız, ancak asıl nokta şu ki - örneğin görüntülerde ne olduğunu öğrenmek için - "açık etiketleme" gerekmez; ChatGPT aslında kendisine verilen metin örneklerinden doğrudan öğrenebilir.
Bir sinir ağındaki gerçek öğrenme süreci ne olacak? Sonunda her şey, verilen eğitim örneklerini en iyi yakalayacak ağırlıkların belirlenmesiyle ilgilidir. Ve bunun nasıl yapıldığını ayarlamak için kullanılabilecek her türlü ayrıntılı seçenek ve "hiperparametre ayarları" (ağırlıklar "parametreler" olarak düşünülebildiği için böyle adlandırılır) vardır. Farklı kayıp fonksiyonu seçenekleri vardır (kareler toplamı, mutlak değerler toplamı, vb.). Kayıp minimizasyonu yapmanın farklı yolları vardır (her adımda ağırlık uzayında ne kadar ilerleneceği vb.). Ve sonra, en aza indirilmeye çalışılan kaybın her bir ardışık tahminini elde etmek için ne kadar büyük bir örnek "yığını" gösterileceği gibi sorular vardır. Ve evet, makine öğrenimini otomatikleştirmek ve hiperparametreler gibi şeyleri otomatik olarak ayarlamak için makine öğrenimi (örneğin Wolfram Language'de yaptığımız gibi) uygulanabilir.
Sonunda tüm eğitim süreci, kaybın giderek nasıl azaldığını görerek karakterize edilebilir (küçük bir eğitim için bu Wolfram Language ilerleme monitöründe olduğu gibi):

Tipik olarak görülen şey, kaybın bir süre azaldığı, ancak sonunda sabit bir değerde düzleştiğidir. Bu değer yeterince küçükse, eğitim başarılı sayılabilir; aksi takdirde muhtemelen ağ mimarisini değiştirmeyi denemek gerektiğinin bir işaretidir.
"Öğrenme eğrisinin" düzleşmesi için ne kadar süre geçmesi gerektiği söylenebilir mi? Diğer pek çok şeyde olduğu gibi, sinir ağının boyutuna ve kullanılan veri miktarına bağlı olan yaklaşık güç yasası ölçeklendirme ilişkileri var gibi görünmektedir. Ancak genel sonuç, bir sinir ağını eğitmenin zor olduğu ve çok fazla hesaplama çabası gerektirdiğidir. Pratik bir konu olarak, bu çabanın büyük çoğunluğu GPU'ların iyi olduğu sayı dizileri üzerinde işlem yapmak için harcanır - bu nedenle sinir ağı eğitimi genellikle GPU'ların kullanılabilirliği ile sınırlıdır.
Gelecekte sinir ağlarını eğitmenin ya da genel olarak sinir ağlarının yaptıklarını yapmanın temelde daha iyi yolları olacak mı? Bence neredeyse kesinlikle. Sinir ağlarının temel fikri, çok sayıda basit (esasen aynı) bileşenden esnek bir "bilgi işlem dokusu" oluşturmak ve bu "dokunun" örneklerden öğrenmek için aşamalı olarak değiştirilebilen bir yapı olmasını sağlamaktır. Mevcut sinir ağlarında, bu aşamalı modifikasyonu yapmak için gerçek sayılara uygulanan kalkülüs fikirleri kullanılmaktadır. Ancak, yüksek hassasiyetli sayılara sahip olmanın önemli olmadığı giderek daha açık hale geliyor; 8 bit veya daha azı mevcut yöntemlerle bile yeterli olabilir.
Hücresel otomatlar gibi temelde çok sayıda bit üzerinde paralel olarak çalışan hesaplama sistemlerinde bu tür artımlı değişikliklerin nasıl yapılacağı hiçbir zaman net olmamıştır, ancak bunun mümkün olmadığını düşünmek için bir neden yoktur. Aslında, "2012'nin derin öğrenme atılımında" olduğu gibi, bu tür artımlı modifikasyon, basit durumlardan daha karmaşık durumlarda etkili bir şekilde daha kolay olacaktır.
Sinir ağları -belki de biraz beyin gibi- esasen sabit bir nöron ağına sahip olacak şekilde kurulur ve değiştirilen şey aralarındaki bağlantıların gücü ("ağırlığı") olur. (Belki de en azından genç beyinlerde önemli sayıda tamamen yeni bağlantılar da büyüyebilir). Ancak bu biyoloji için uygun bir düzen olsa da, ihtiyacımız olan işlevselliği elde etmenin en iyi yoluna yakın olduğu hiç de açık değildir. Ve aşamalı ağ yeniden yazımının eşdeğerini içeren bir şey (belki de Fizik Projemizi anımsatan) sonuçta daha iyi olabilir.
Ancak mevcut sinir ağları çerçevesinde bile şu anda çok önemli bir sınırlama var: Şu anda yapıldığı şekliyle sinir ağı eğitimi temelde sıralıdır ve her bir örnek grubunun etkileri ağırlıkları güncellemek için geri yayılır. Ve gerçekten de mevcut bilgisayar donanımıyla - GPU'ları hesaba katsak bile - bir sinir ağının çoğu, eğitim sırasında çoğu zaman "boşta" kalır ve her seferinde yalnızca bir parça güncellenir. Bir anlamda bunun nedeni, mevcut bilgisayarlarımızın CPU'larından (veya GPU'larından) ayrı bir belleğe sahip olma eğiliminde olmalarıdır. Ancak beyinlerde durum muhtemelen farklıdır; her "bellek öğesi" (yani nöron) aynı zamanda potansiyel olarak aktif bir hesaplama öğesidir. Gelecekteki bilgisayar donanımımızı bu şekilde kurabilirsek, eğitimi çok daha verimli bir şekilde yapmak mümkün olabilir.
"Yeterince Büyük Bir Ağ Elbette Her Şeyi Yapabilir!"
ChatGPT gibi bir şeyin yetenekleri o kadar etkileyici görünüyor ki, insan "devam edip" daha büyük sinir ağlarını eğitebilirse, sonunda "her şeyi yapabileceklerini" hayal edebilir. Ve eğer insan düşüncesinin hemen erişebileceği şeylerle ilgileniliyorsa, durumun böyle olması oldukça olasıdır. Ancak bilimin son birkaç yüz yılından çıkarılan ders, biçimsel süreçlerle çözülebilen ancak insan düşüncesinin hemen erişemeyeceği şeyler olduğudur.
Önemsiz matematik buna büyük bir örnektir. Ancak genel durum gerçekten hesaplamadır. Nihayetinde mesele, hesaplamaya indirgenemezlik olgusudur. Bazı hesaplamalar vardır ki, yapılması için birçok adım atılması gerektiği düşünülebilir, ancak bunlar aslında oldukça hızlı bir şekilde "indirgenebilir". Ancak hesaplama indirgenemezliğinin keşfi, bunun her zaman işe yaramadığını ima etmektedir. Bunun yerine -muhtemelen aşağıdaki gibi- ne olduğunu anlamanın kaçınılmaz olarak her bir hesaplama adımını izlemeyi gerektirdiği süreçler vardır:

Normalde beynimizle yaptığımız türden şeyler, muhtemelen hesaplama indirgenemezliğinden kaçınmak için özellikle seçilmiştir. Birinin beyninde matematik yapmak özel bir çaba gerektirir. Pratikte, önemsiz olmayan herhangi bir programın işleyişindeki adımları sadece beyinde "düşünmek" büyük ölçüde imkansızdır.
Elbette bunun için bilgisayarlarımız var. Bilgisayarlarla uzun, hesaplama açısından indirgenemez şeyleri kolayca yapabiliriz. Kilit nokta, genel olarak bunlar için bir kestirme yol olmamasıdır.
Belirli bir hesaplama sisteminde neler olduğuna dair pek çok spesifik örneği ezberleyebiliriz. Belki biraz genelleme yapmamızı sağlayacak bazı ("hesaplamaya indirgenebilir") kalıplar bile görebiliriz. Mesele şu ki, hesaplama indirgenemezliği, beklenmedik şeylerin olmayacağını asla garanti edemeyeceğimiz anlamına gelir ve herhangi bir özel durumda gerçekte ne olduğunu ancak hesaplamayı açıkça yaparak söyleyebilirsiniz.
Sonuçta öğrenilebilirlik ile hesaplama indirgenemezliği arasında temel bir gerilim vardır. Öğrenme, aslında düzenliliklerden yararlanarak veriyi sıkıştırmayı içerir. Hesaplama indirgenemezliği, nihayetinde hangi düzenliliklerin olabileceğinin bir sınırı olduğunu ima eder.
Pratik bir konu olarak, sinir ağları gibi eğitilebilir sistemlere hücresel otomatlar veya Turing makineleri gibi küçük hesaplama cihazları inşa etmek düşünülebilir. Gerçekten de bu tür cihazlar sinir ağları için iyi birer "araç" olabilirler; WolframAlpha'nın ChatGPT için iyi bir araç olması gibi. Hesaplama indirgenemezliği, bu cihazların "içine girmenin" ve öğrenmelerini sağlamanın beklenemeyeceği anlamına gelir.
Ya da başka bir deyişle, yetenek ve eğitilebilirlik arasında nihai bir değiş tokuş vardır: bir sistemin hesaplama yeteneklerini "gerçek anlamda" kullanmasını ne kadar çok isterseniz, o kadar çok hesaplama indirgenemezliği gösterecek ve o kadar az eğitilebilir olacaktır. Temelde ne kadar eğitilebilirse, o kadar az sofistike hesaplama yapabilecektir.
(Şu anki haliyle ChatGPT için durum aslında çok daha aşırıdır, çünkü her bir çıktı belirtecini üretmek için kullanılan sinir ağı, döngüler olmadan saf bir "ileri besleme" ağıdır ve bu nedenle önemsiz "kontrol akışı" ile herhangi bir hesaplama yapma yeteneğine sahip değildir).
Elbette, indirgenemez hesaplamalar yapabilmenin gerçekten önemli olup olmadığı merak edilebilir. Gerçekten de insanlık tarihinin büyük bir bölümünde bu pek de önemli değildi. Ancak modern teknolojik dünyamız, en azından matematiksel hesaplamalardan ve giderek daha genel hesaplamalardan yararlanan mühendislik üzerine inşa edilmiştir. Ve doğal dünyaya bakarsak, indirgenemez hesaplamalarla dolu olduğunu görürüz; bunları nasıl taklit edeceğimizi ve teknolojik amaçlarımız için nasıl kullanacağımızı yavaş yavaş anlıyoruz.
Bir sinir ağı, doğal dünyada "yardımsız insan düşüncesi" ile de kolayca fark edebileceğimiz türden düzenlilikleri kesinlikle fark edebilir. Ancak matematiksel veya hesaplamalı bilimin alanına giren şeyleri çözmek istiyorsak, sinir ağı bunu yapamayacaktır - "sıradan" bir hesaplama sistemini etkin bir şekilde "araç olarak kullanmadığı" sürece.
Ancak tüm bunlarda potansiyel olarak kafa karıştırıcı bir şey var. Geçmişte, deneme yazmak da dahil olmak üzere, bilgisayarlar için bir şekilde "temelde çok zor" olduğunu varsaydığımız pek çok görev vardı. Şimdi bunların ChatGPT gibileri tarafından yapıldığını gördüğümüzde, aniden bilgisayarların çok daha güçlü hale gelmesi gerektiğini düşünme eğilimindeyiz - özellikle de temelde zaten yapabildikleri şeyleri aşarak (hücresel otomatlar gibi hesaplama sistemlerinin davranışını aşamalı olarak hesaplamak gibi).
Bu çıkarılacak doğru sonuç değildir. Hesaplamalı olarak indirgenemez süreçler hala hesaplamalı olarak indirgenemezdir ve bilgisayarlar için hala temelde zordur - bilgisayarlar bunların bireysel adımlarını kolayca hesaplayabilse bile. Bunun yerine varmamız gereken sonuç, deneme yazmak gibi biz insanların yapabildiği ama bilgisayarların yapamayacağını düşündüğümüz görevlerin aslında bir anlamda hesaplama açısından düşündüğümüzden daha kolay olduğudur.
Başka bir deyişle, bir sinir ağının makale yazmada başarılı olabilmesinin nedeni, makale yazmanın düşündüğümüzden "hesaplama açısından daha sığ" bir problem olduğunun ortaya çıkmasıdır. Ve bir anlamda bu bizi, biz insanların deneme yazmak gibi şeyleri nasıl başardığımıza ya da genel olarak dille nasıl başa çıktığımıza dair bir "teoriye sahip olmaya" yaklaştırıyor.
Eğer yeterince büyük bir sinir ağınız olsaydı, insanların kolayca yapabildiği her şeyi yapabilirdiniz. Ancak genel olarak doğal dünyanın yapabildiklerini ya da doğal dünyadan oluşturduğumuz araçların yapabildiklerini yakalayamazdınız. Son yüzyıllarda "saf yardımsız insan düşüncesi" için erişilebilir olanın sınırlarını aşmamızı ve fiziksel ve hesaplamalı evrende var olanın daha fazlasını insan amaçları için yakalamamızı sağlayan şey, hem pratik hem de kavramsal olan bu araçların kullanımıdır.
Gömme Kavramı
Sinir ağları -en azından şu anda kuruldukları şekliyle- temelde sayılara dayanmaktadır. Dolayısıyla onları metin gibi bir şey üzerinde çalışmak için kullanacaksak, metnimizi sayılarla temsil etmenin bir yoluna ihtiyacımız olacaktır. Elbette (esasen ChatGPT'nin yaptığı gibi) sözlükteki her kelimeye bir numara atayarak başlayabiliriz. Ancak bunun ötesine geçen -örneğin ChatGPT'nin merkezinde yer alan- önemli bir fikir var. Bu da "gömme" fikridir. Gömme, bir şeyin "özünü" bir dizi sayı ile temsil etmeye çalışmanın bir yolu olarak düşünülebilir - "yakındaki şeylerin" yakındaki sayılarla temsil edilmesi özelliği ile.
Örneğin, bir sözcük katıştırmasını, sözcükleri bir tür "anlam uzayı "na yerleştirmeye çalışmak olarak düşünebiliriz; bu uzayda bir şekilde "anlam olarak yakın" olan sözcükler katıştırmada yakın görünür. Örneğin ChatGPT'de kullanılan gerçek katıştırmalar büyük sayı listelerini içerme eğilimindedir. Ancak iki boyuta yansıtırsak, sözcüklerin yerleştirme tarafından nasıl düzenlendiğine dair örnekler gösterebiliriz:

Gördüklerimiz tipik günlük izlenimleri yakalamakta oldukça başarılıdır. Peki böyle bir yerleştirmeyi nasıl oluşturabiliriz? Kabaca fikir, büyük miktarda metne (burada web'den 5 milyar kelime) bakmak ve ardından farklı kelimelerin göründüğü "ortamların" "ne kadar benzer" olduğunu görmektir. Örneğin, "timsah" ve "timsah" genellikle benzer cümlelerde neredeyse birbirinin yerine geçecek şekilde görünür ve bu da gömme işleminde yakın yerleştirilecekleri anlamına gelir. Ancak "şalgam" ve "kartal" benzer cümlelerde görünme eğiliminde olmayacaktır, bu nedenle yerleştirmede birbirinden uzakta yer alacaklardır.
Peki sinir ağları kullanılarak böyle bir şey nasıl gerçekleştirilebilir? Sözcükler için değil, görüntüler için katıştırmalardan bahsederek başlayalım. Görüntüleri sayı listeleriyle karakterize etmenin bir yolunu bulmak istiyoruz, öyle ki "benzer olduğunu düşündüğümüz görüntülere" benzer sayı listeleri atansın.
"Görüntüleri benzer kabul etmemiz" gerektiğini nasıl anlayacağız? Diyelim ki görüntülerimiz el yazısı rakamlardan oluşuyorsa, aynı rakama ait iki görüntüyü "benzer kabul edebiliriz". Daha önce el yazısı rakamları tanımak üzere eğitilmiş bir sinir ağından bahsetmiştik. Bu sinir ağının, nihai çıktısında görüntüleri her rakam için bir tane olmak üzere 10 farklı kutuya koyacak şekilde ayarlandığını düşünebiliriz.
Peki ya son "bu bir '4'" kararı verilmeden önce sinir ağının içinde neler olup bittiğine "müdahale edersek" ne olur? Sinir ağının içinde görüntüleri "çoğunlukla 4 benzeri ama biraz da 2 benzeri" olarak niteleyen sayılar olmasını bekleyebiliriz. Buradaki fikir, bu tür sayıları toplayıp bir gömme işleminde öğe olarak kullanmaktır.
İşte konsept. Doğrudan "hangi görüntünün hangi görüntüye yakın olduğunu" karakterize etmeye çalışmak yerine, açık eğitim verilerini alabileceğimiz iyi tanımlanmış bir görevi (bu durumda rakam tanıma) ele alıyoruz - sonra bu görevi yaparken sinir ağının dolaylı olarak "yakınlık kararları" vermesi gerektiği gerçeğini kullanıyoruz. Yani "görüntülerin yakınlığı" hakkında açıkça konuşmak zorunda kalmak yerine, sadece bir görüntünün hangi rakamı temsil ettiği somut sorusundan bahsediyoruz ve sonra bunun "görüntülerin yakınlığı" hakkında ne anlama geldiğini dolaylı olarak belirlemeyi "sinir ağına bırakıyoruz".
Peki bu durum rakam tanıma ağı için daha ayrıntılı olarak nasıl işliyor? Ağın birbirini takip eden 11 katmandan oluştuğunu düşünebiliriz, bunu simgesel olarak şu şekilde özetleyebiliriz (aktivasyon fonksiyonları ayrı katmanlar olarak gösterilmiştir):
Başlangıçta ilk katmana, piksel değerlerinin 2 boyutlu dizileriyle temsil edilen gerçek görüntüleri besliyoruz. Ve en sonunda -son katmandan- 10 değerden oluşan bir dizi elde ediyoruz, bu da ağın görüntünün 0'dan 9'a kadar olan rakamların her birine karşılık geldiğinden "ne kadar emin" olduğunu söyleyebiliriz.
4 ile görüntüyü besleyin ve son katmandaki nöronların değerleri şöyledir:

Başka bir deyişle, sinir ağı bu noktada bu görüntünün 4 olduğundan "inanılmaz derecede emin" - ve aslında "4" çıktısını almak için sadece en büyük değere sahip nöronun konumunu seçmemiz gerekiyor.
Ama bir adım öncesine bakarsak ne olur? Ağdaki en son işlem, "kesinliği zorlamaya" çalışan softmax adı verilen bir işlemdir. Ancak bu uygulanmadan önce nöronların değerleri şöyledir:

"4 "ü temsil eden nöron hala en yüksek sayısal değere sahiptir. Ancak diğer nöronların değerlerinde de bilgi vardır. Bu sayı listesinin bir anlamda görüntünün "özünü" karakterize etmek için kullanılabileceğini ve böylece bir gömme olarak kullanabileceğimiz bir şey sağlayabileceğini bekleyebiliriz. Örneğin, buradaki 4'lerin her biri 8'lerden çok farklı bir "imzaya" (ya da "özellik gömme") sahiptir:

Burada resimlerimizi karakterize etmek için esasen 10 sayı kullanıyoruz. Ancak genellikle bundan çok daha fazlasını kullanmak daha iyidir. Örneğin rakam tanıma ağımızda, bir önceki katmana dokunarak 500 rakamdan oluşan bir dizi elde edebiliriz. Bu muhtemelen "görüntü gömme" olarak kullanmak için makul bir dizidir.
El yazısı rakamlar için "görüntü uzayı "nın açık bir görselleştirmesini yapmak istiyorsak, elimizdeki 500 boyutlu vektörü örneğin 3 boyutlu uzaya yansıtarak etkili bir şekilde "boyutu azaltmamız" gerekir:

Az önce, (eğitim setimize göre) aynı el yazısı rakamına karşılık gelip gelmediklerini belirleyerek görüntülerin benzerliğini tanımlamaya dayanan görüntüler için bir karakterizasyon (ve dolayısıyla gömme) oluşturmaktan bahsettik. Aynı şeyi, örneğin her bir görüntünün 5000 yaygın nesne türünden (kedi, köpek, sandalye, ...) hangisine ait olduğunu belirleyen bir eğitim setimiz varsa, görüntüler için çok daha genel olarak yapabiliriz. Bu şekilde, ortak nesneleri tanımlamamızla "sabitlenen", ancak daha sonra sinir ağının davranışına göre "bunun etrafında genelleşen" bir görüntü gömme yapabiliriz. Mesele şu ki, bu davranış biz insanların görüntüleri nasıl algıladığı ve yorumladığı ile uyumlu olduğu ölçüde, bu "bize doğru görünen" ve pratikte "insan yargısı benzeri" görevleri yerine getirmede yararlı olan bir gömme olacaktır.
Kelimeler için katıştırmalar bulmak için aynı türden bir yaklaşımı nasıl izleyebiliriz? İşin anahtarı, sözcükler hakkında kolayca eğitim alabileceğimiz bir görevden başlamaktır. Ve bu tür standart görev "kelime tahminidir". Bize "___ kedisi" verildiğini düşünün. Geniş bir metin külliyatına (örneğin, web'deki metin içeriği) dayanarak, "boşluğu doldurabilecek" farklı sözcükler için olasılıklar nelerdir? Ya da alternatif olarak, "___ siyah ___" verildiğinde, farklı "yan kelimeler" için olasılıklar nelerdir?
Bu problemi bir sinir ağı için nasıl kurabiliriz? Sonuçta her şeyi sayılar cinsinden formüle etmek zorundayız. Bunu yapmanın bir yolu da İngilizce'deki 50.000 kadar yaygın kelimenin her birine benzersiz bir sayı atamaktır. Örneğin, "the" 914 olabilir ve "cat" (önünde bir boşluk ile) 3542 olabilir. (Ve bunlar GPT-2 tarafından kullanılan gerçek sayılardır.) Yani "the ___ cat" problemi için girdimiz {914, 3542} olabilir. Çıktı nasıl olmalıdır? Olası "doldurma" kelimelerinin her biri için olasılıkları etkin bir şekilde veren 50.000 kadar sayıdan oluşan bir liste olmalıdır. Ve bir kez daha, bir gömme bulmak için, sinir ağının "sonuca ulaşmadan" hemen önce "içini" "kesmek" istiyoruz - ve sonra orada ortaya çıkan ve "her kelimeyi karakterize eden" olarak düşünebileceğimiz sayıların listesini almak istiyoruz.
Bu karakterizasyonlar neye benziyor? Son 10 yılda, her biri farklı bir sinir ağı yaklaşımına dayanan bir dizi farklı sistem geliştirildi (word2vec, GloVe, BERT, GPT, ...). Ancak sonuçta hepsi kelimeleri alıyor ve onları yüzlerce ila binlerce sayıdan oluşan listelerle karakterize ediyor.
Ham halleriyle, bu "gömme vektörleri" oldukça bilgilendirici değildir. Örneğin, GPT-2'nin üç belirli kelime için ham gömme vektörleri olarak ürettiği şey burada:

Bu vektörler arasındaki mesafeleri ölçmek gibi şeyler yaparsak, kelimelerin "yakınlıkları" gibi şeyler bulabiliriz. Daha sonra bu tür yerleştirmelerin "bilişsel" önemini daha ayrıntılı olarak tartışacağız. Ancak şimdilik asıl önemli nokta, kelimeleri "sinir ağı dostu" sayı koleksiyonlarına dönüştürmenin bir yolunu bulmuş olmamızdır.
Ama aslında sözcükleri sayı koleksiyonlarıyla karakterize etmekten daha ileri gidebiliriz; bunu sözcük dizileri veya aslında tüm metin blokları için de yapabiliriz. ChatGPT'nin içinde de işler bu şekilde yürüyor. Şu ana kadar elde ettiği metni alır ve onu temsil etmek için bir gömme vektörü oluşturur. Daha sonra amacı, daha sonra ortaya çıkabilecek farklı kelimeler için olasılıkları bulmaktır. Ve bunun için cevabını, esasen 50.000 kadar olası kelimenin her biri için olasılıkları veren bir sayı listesi olarak temsil eder.
(Açıkçası, ChatGPT kelimelerle değil, daha ziyade "belirteçlerle" -tüm kelimeler veya sadece "pre" veya "ing" veya "ized" gibi parçalar olabilen uygun dilsel birimlerle- ilgilenir. Jetonlarla çalışmak ChatGPT'nin nadir, bileşik ve İngilizce olmayan sözcüklerle başa çıkmasını ve bazen iyi ya da kötü yeni sözcükler icat etmesini kolaylaştırır).
Inside ChatGPT
Sonunda ChatGPT'nin içinde ne olduğunu tartışmaya hazırız. Nihayetinde bu dev bir sinir ağı - şu anda GPT-3 ağının 175 milyar ağırlığa sahip bir versiyonu. Birçok yönden bu, tartıştığımız diğerlerine çok benzeyen bir sinir ağı. Özellikle dil ile uğraşmak için kurulmuş bir sinir ağıdır. En dikkat çekici özelliği "transformatör" adı verilen bir sinir ağı mimarisi parçasıdır.
Yukarıda tartıştığımız ilk sinir ağlarında, herhangi bir katmandaki her nöron temelde bir önceki katmandaki her nörona (en azından bir miktar ağırlıkla) bağlıydı. Ancak bu tür bir tam bağlantılı ağ, belirli, bilinen bir yapıya sahip verilerle çalışılıyorsa (muhtemelen) aşırıdır. Bu nedenle, örneğin, görüntülerle çalışmanın ilk aşamalarında, nöronların görüntüdeki piksellere benzer bir ızgara üzerine etkili bir şekilde yerleştirildiği ve yalnızca ızgaradaki yakın nöronlara bağlandığı sözde evrişimli sinir ağları ("convnets") kullanmak tipiktir.
Dönüştürücüler fikri, bir metin parçasını oluşturan belirteç dizileri için en azından biraz benzer bir şey yapmaktır. Ancak, dizide bağlantıların olabileceği sabit bir bölge tanımlamak yerine, dönüştürücüler bunun yerine "dikkat" kavramını ve dizinin bazı bölümlerine diğerlerinden daha fazla "dikkat etme" fikrini ortaya koyar. Belki bir gün sadece genel bir sinir ağı başlatmak ve tüm özelleştirmeyi eğitim yoluyla yapmak mantıklı olacaktır. Ancak en azından şu an için, transformatörlerin ve muhtemelen beynimizin de yaptığı gibi, şeyleri "modülerleştirmek" pratikte kritik gibi görünüyor.
ChatGPT (ya da daha doğrusu temel aldığı GPT-3 ağı) gerçekte ne yapar? Genel amacının, aldığı eğitimden gördüklerine dayanarak metni "makul" bir şekilde devam ettirmek olduğunu hatırlayın (bu, web'den milyarlarca sayfa metne bakmaktan ibarettir, vb.) Dolayısıyla, herhangi bir noktada, belirli miktarda metin vardır ve amacı, eklenecek bir sonraki belirteç için uygun bir seçim yapmaktır.
Üç temel aşamada çalışır. İlk olarak, şu ana kadar metne karşılık gelen belirteç dizisini alır ve bunları temsil eden bir gömme (yani bir sayı dizisi) bulur. Daha sonra, yeni bir gömme (yani yeni bir sayı dizisi) üretmek için bu gömme üzerinde "standart sinir ağı yöntemiyle", bir ağdaki ardışık katmanlar arasında "dalgalanan" değerlerle çalışır. Daha sonra bu dizinin son bölümünü alır ve ondan sonraki farklı olası belirteçler için olasılıklara dönüşen yaklaşık 50.000 değerden oluşan bir dizi üretir. (İngilizcede yaygın olarak kullanılan kelimelerle yaklaşık aynı sayıda belirteç kullanılmasına rağmen, belirteçlerin sadece yaklaşık 3000'i tam kelimedir ve geri kalanı parçalardır).
Kritik bir nokta, bu boru hattının her bir parçasının, ağırlıkları ağın uçtan uca eğitimi ile belirlenen bir sinir ağı tarafından uygulanmasıdır. Başka bir deyişle, aslında genel mimari dışında hiçbir şey "açıkça tasarlanmamıştır"; her şey eğitim verilerinden "öğrenilmiştir".
Bununla birlikte, mimarinin kurulma biçiminde her türlü deneyimi ve sinir ağı bilgisini yansıtan pek çok ayrıntı vardır. Ve - bu kesinlikle yabani otlara giriyor olsa da - bu ayrıntılardan bazıları hakkında konuşmanın yararlı olduğunu düşünüyorum, en azından ChatGPT gibi bir şey inşa etmek için neler yapıldığına dair bir fikir edinmek için.
İlk olarak gömme modülü geliyor. İşte GPT-2 için şematik bir Wolfram Dili gösterimi:

Girdi, n jetondan oluşan bir vektördür (önceki bölümde olduğu gibi 1'den yaklaşık 50.000'e kadar tam sayılarla temsil edilir). Bu belirteçlerin her biri (tek katmanlı bir sinir ağı tarafından) bir gömme vektörüne (GPT-2 için 768 ve ChatGPT'nin GPT-3'ü için 12.288 uzunluğunda) dönüştürülür. Bu arada, belirteçler için (tamsayı) konum dizisini alan ve bu tamsayılardan başka bir gömme vektörü oluşturan bir "ikincil yol" vardır. Ve son olarak, token değeri ve token pozisyonundan gelen gömme vektörleri, gömme modülünden gelen son gömme vektörleri dizisini üretmek için birbirine eklenir.
Neden sadece token-değeri ve token-konumu gömme vektörleri bir araya getiriliyor? Bunun belirli bir bilimsel yanı olduğunu sanmıyorum. Sadece çeşitli farklı şeyler denendi ve bu işe yarıyor gibi görünüyor. Ve sinir ağları ilminin bir parçası olarak - bir anlamda - sahip olunan kurulum "kabaca doğru" olduğu sürece, sinir ağının kendisini nasıl yapılandırdığını gerçekten "mühendislik düzeyinde anlamaya" gerek kalmadan, sadece yeterli eğitim yaparak ayrıntılara odaklanmak genellikle mümkündür.
İşte gömme modülünün hello hello hello hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye bye bye bye bye bye dizesi üzerinde yaptığı işlem

Her bir token için gömme vektörünün elemanları sayfanın aşağısında gösterilmektedir ve sayfa boyunca önce bir dizi "hello" gömme, ardından da bir dizi "bye" gömme görmekteyiz. Yukarıdaki ikinci dizi konumsal katıştırmadır - biraz rastgele görünen yapısı sadece "öğrenilen" şeydir (bu durumda GPT-2'de).
Tamam, gömme modülünden sonra dönüştürücünün "ana olayı" geliyor: "dikkat blokları" olarak adlandırılan bir dizi (GPT-2 için 12, ChatGPT'nin GPT-3'ü için 96). Her şey oldukça karmaşık ve anlaşılması zor tipik büyük mühendislik sistemlerini ya da bu bağlamda biyolojik sistemleri anımsatıyor. Ama her neyse, işte tek bir "dikkat bloğunun" şematik gösterimi (GPT-2 için):

Bu tür her bir dikkat bloğu içinde, her biri gömme vektöründeki farklı değer yığınları üzerinde bağımsız olarak çalışan bir dizi "dikkat kafası" (GPT-2 için 12, ChatGPT'nin GPT-3'ü için 96) vardır. (Ve evet, gömme vektörünü bölmenin neden iyi bir fikir olduğunu ya da farklı parçalarının "ne anlama geldiğini" bilmiyoruz; bu sadece "işe yaradığı tespit edilen" şeylerden biri).
Peki, dikkat başlıkları ne işe yarar? Temel olarak, belirteçler dizisinde (yani şimdiye kadar üretilen metinde) "geriye bakmanın" ve bir sonraki belirteci bulmak için yararlı bir biçimde "geçmişi paketlemenin" bir yoludur. Yukarıdaki ilk bölümde, kendilerinden hemen önceki sözcükleri seçmek için 2-gram olasılıklarını kullanmaktan bahsetmiştik. Dönüştürücülerdeki "dikkat" mekanizmasının yaptığı şey, çok daha önceki kelimelere bile "dikkat" edilmesine izin vermektir - böylece, örneğin, fiillerin bir cümlede kendilerinden birçok kelime önce görünen isimlere atıfta bulunma şeklini potansiyel olarak yakalayabilir.
Daha ayrıntılı bir düzeyde, bir dikkat kafasının yaptığı şey, farklı belirteçlerle ilişkili gömme vektörlerindeki parçaları belirli ağırlıklarla yeniden birleştirmektir. Örneğin, ilk dikkat bloğundaki (GPT-2'deki) 12 dikkat kafası, yukarıdaki "hello, bye" dizesi için aşağıdaki ("look-back-all-the-way-to-the-beginning-of-the-sequence-of-tokens") "yeniden birleştirme ağırlıkları" modellerine sahiptir:

Dikkat kafaları tarafından işlendikten sonra, ortaya çıkan "yeniden ağırlıklandırılmış gömme vektörü" (GPT-2 için 768 uzunluğunda ve ChatGPT'nin GPT-3'ü için 12.288 uzunluğunda) standart bir "tam bağlı" sinir ağı katmanından geçirilir. Bu katmanın ne yaptığını anlamak zor. Ancak burada kullandığı ağırlıkların 768×768 matrisinin bir grafiği var (burada GPT-2 için):


Bu yapıyı belirleyen nedir? Sonuçta muhtemelen insan dilinin özelliklerinin bir "sinir ağı kodlaması". Ancak şu an itibariyle bu özelliklerin neler olabileceği bilinmiyor. Gerçekte, "ChatGPT'nin (ya da en azından GPT-2'nin) beynini açıyoruz" ve keşfediyoruz ki, evet, orası karmaşık ve biz onu anlamıyoruz - sonuçta tanınabilir bir insan dili üretiyor olsa bile.
Tamam, bir dikkat bloğundan geçtikten sonra, yeni bir gömme vektörümüz oluyor - bu vektör daha sonra art arda ek dikkat bloklarından geçiyor (GPT-2 için toplam 12; GPT-3 için 96). Her dikkat bloğunun kendine özgü "dikkat" ve "tam bağlı" ağırlıkları vardır. Burada GPT-2 için "hello, bye" girdisine yönelik dikkat ağırlıkları dizisi, ilk dikkat başlığı için verilmiştir:

Ve işte tam bağlantılı katmanlar için (hareketli ortalamalı) "matrisler":

İlginçtir ki, farklı dikkat bloklarındaki bu "ağırlık matrisleri" oldukça benzer görünse de, ağırlıkların boyutlarının dağılımları biraz farklı olabilir (ve her zaman Gauss değildir):

Peki tüm bu dikkat bloklarından geçtikten sonra dönüştürücünün net etkisi nedir? Esasen, belirteçler dizisi için orijinal gömme koleksiyonunu nihai bir koleksiyona dönüştürmektir. ChatGPT'nin özel çalışma şekli ise bu koleksiyondaki son katıştırmayı almak ve bir sonraki belirtecin ne olması gerektiğine dair bir olasılık listesi üretmek için onu "çözmektir".
ChatGPT'nin içinde ne olduğu ana hatlarıyla bu şekildedir. Karmaşık görünebilir (en azından kaçınılmaz olarak biraz keyfi "mühendislik seçimleri" nedeniyle), ancak aslında ilgili nihai unsurlar oldukça basittir. Çünkü sonuçta uğraştığımız şey "yapay nöronlardan" oluşan bir sinir ağıdır ve her biri sayısal girdilerden oluşan bir koleksiyonu alıp bunları belirli ağırlıklarla birleştirmek gibi basit bir işlem yapar.
ChatGPT'nin orijinal girdisi bir dizi sayıdır (şimdiye kadarki belirteçler için gömme vektörleri) ve ChatGPT yeni bir belirteç üretmek için "çalıştığında" olan şey, bu sayıların sinir ağının katmanlarında "dalgalanması", her nöronun "işini yapması" ve sonucu bir sonraki katmandaki nöronlara aktarmasıdır. Döngü ya da "geri dönüş" yoktur. Her şey sadece ağ üzerinden "ileriye doğru beslenir".
Bu, sonuçların aynı hesaplama öğeleri tarafından tekrar tekrar "yeniden işlendiği" Turing makinesi gibi tipik bir hesaplama sisteminden çok farklı bir kurulumdur. Burada -en azından belirli bir çıktı belirtecinin üretilmesinde- her hesaplama öğesi (yani nöron) yalnızca bir kez kullanılır.
Ancak ChatGPT'de bile bir anlamda hesaplama elemanlarını yeniden kullanan bir "dış döngü" vardır. Çünkü ChatGPT yeni bir belirteç üreteceği zaman, ChatGPT'nin daha önce "yazdığı" belirteçler de dahil olmak üzere, kendisinden önce gelen tüm belirteç dizisini her zaman "okur" (yani girdi olarak alır). Ve bu kurulumu ChatGPT'nin -en azından en dış seviyesinde- bir "geri bildirim döngüsü" içerdiği, ancak her yinelemenin ürettiği metinde görünen bir belirteç olarak açıkça görülebildiği anlamına geldiği şeklinde düşünebiliriz.
Ancak ChatGPT'nin özüne geri dönelim: her bir jetonu üretmek için tekrar tekrar kullanılan sinir ağı. Bir düzeyde çok basit: birbirinin aynı yapay nöronlardan oluşan bir koleksiyon. Ve ağın bazı kısımları, belirli bir katmandaki her nöronun bir önceki katmandaki her nörona (bir miktar ağırlıkla) bağlı olduğu ("tam bağlantılı") nöron katmanlarından oluşur. Ancak özellikle transformatör mimarisi ile ChatGPT, yalnızca farklı katmanlardaki belirli nöronların bağlı olduğu daha fazla yapıya sahip parçalara sahiptir. (Tabii ki, hala "tüm nöronlar birbirine bağlıdır" denebilir - ancak bazılarının sadece sıfır ağırlığı vardır).
Buna ek olarak, ChatGPT'deki sinir ağının doğal olarak sadece "homojen" katmanlardan oluştuğu düşünülmeyen yönleri de vardır. Örneğin, yukarıdaki ikonik özette de belirtildiği gibi, bir dikkat bloğunun içinde, gelen verilerin "birden fazla kopyasının yapıldığı", her birinin farklı bir "işleme yolundan" geçtiği, potansiyel olarak farklı sayıda katman içerdiği ve ancak daha sonra yeniden birleştirildiği yerler vardır. Ancak bu, neler olup bittiğinin uygun bir temsili olsa da, en azından prensipte katmanları "yoğun bir şekilde doldurmayı" düşünmek her zaman mümkündür, ancak sadece bazı ağırlıkların sıfır olması gerekir.
ChatGPT'deki en uzun yola bakacak olursak, yaklaşık 400 (çekirdek) katman söz konusudur - bazı açılardan çok büyük bir sayı değildir. Ancak toplam 175 milyar bağlantı ve dolayısıyla 175 milyar ağırlığa sahip milyonlarca nöron vardır. ChatGPT'nin her yeni token ürettiğinde, bu ağırlıkların her birini içeren bir hesaplama yapması gerektiğinin farkına varılması gerekir. Uygulamada bu hesaplamalar, GPU'larda rahatlıkla yapılabilecek son derece paralel dizi işlemlerinde "katmana göre" bir şekilde organize edilebilir. Ancak üretilen her bir belirteç için yine de 175 milyar hesaplama yapılması gerekiyor (ve sonuçta biraz daha fazla) - bu nedenle, evet, ChatGPT ile uzun bir metin parçasının oluşturulmasının biraz zaman alması şaşırtıcı değil.
Ancak sonuçta dikkat çekici olan, tüm bu işlemlerin - tek tek ne kadar basit olsalar da - bir şekilde birlikte metin üretme konusunda bu kadar iyi bir "insan benzeri" iş çıkarmayı başarabilmeleridir. Tekrar vurgulamak gerekir ki (en azından bildiğimiz kadarıyla) böyle bir şeyin neden çalışması gerektiğine dair "nihai bir teorik neden" yoktur. Ve aslında, tartışacağımız gibi, bence bunu -potansiyel olarak şaşırtıcı- bilimsel bir keşif olarak görmeliyiz: ChatGPT'ninki gibi bir sinir ağında bir şekilde insan beyninin dil üretirken yapmayı başardığı şeyin özünü yakalamak mümkündür.
ChatGPT'nin Eğitimi
Tamam, şimdi ChatGPT'nin kurulduktan sonra nasıl çalıştığının ana hatlarını verdik. Ama nasıl kuruldu? Sinir ağındaki tüm bu 175 milyar ağırlık nasıl belirlendi? Temel olarak bunlar, insanlar tarafından yazılmış web'deki, kitaplardaki vb. büyük bir metin külliyatına dayanan çok büyük ölçekli bir eğitimin sonucudur. Söylediğimiz gibi, tüm bu eğitim verileri göz önüne alındığında bile, bir sinir ağının başarılı bir şekilde "insan benzeri" metin üretebileceği kesinlikle açık değildir. Ve bir kez daha, bunun gerçekleşmesi için ayrıntılı mühendislik parçalarına ihtiyaç var gibi görünüyor. Ancak ChatGPT'nin en büyük sürprizi ve keşfi bunun mümkün olması. Ve aslında "sadece" 175 milyar ağırlığa sahip bir sinir ağı, insanların yazdığı metnin "makul bir modelini" oluşturabilir.
Modern zamanlarda, insanlar tarafından yazılmış ve dijital formda bulunan çok sayıda metin var. Herkese açık web'de insan eliyle yazılmış en az birkaç milyar sayfa ve toplamda belki de bir trilyon kelime metin bulunmaktadır. Kamuya açık olmayan web sayfaları da dahil edilirse, bu rakam en az 100 kat daha büyük olabilir. Şimdiye kadar 5 milyondan fazla dijitalleştirilmiş kitap kullanıma sunuldu (şimdiye kadar yayınlanmış 100 milyon kadar kitaptan), bu da 100 milyar kadar kelime daha metin anlamına geliyor. (Kişisel bir karşılaştırma yapmak gerekirse, hayatım boyunca yayınladığım toplam metin 3 milyon kelimenin biraz altında ve son 30 yılda yaklaşık 15 milyon kelime e-posta yazdım ve toplamda belki de 50 milyon kelime yazdım - ve sadece son birkaç yılda canlı yayınlarda 10 milyon kelimeden fazla konuştum. Ve evet, tüm bunlardan bir bot eğiteceğim).
Peki, tüm bu veriler göz önüne alındığında, bir sinir ağı nasıl eğitilir? Temel süreç, yukarıdaki basit örneklerde tartıştığımız gibidir. Bir grup örnek sunarsınız ve ardından ağın bu örnekler üzerinde yaptığı hatayı ("kayıp") en aza indirmek için ağdaki ağırlıkları ayarlarsınız. Hatadan "geri yayılma" ile ilgili pahalı olan ana şey, bunu her yaptığınızda, ağdaki her ağırlığın tipik olarak en azından küçük bir miktar değişecek olması ve uğraşılması gereken çok fazla ağırlık olmasıdır. (Gerçek "geri hesaplama" tipik olarak ileriye doğru olandan sadece küçük bir sabit faktör daha zordur).
Modern GPU donanımı ile binlerce örnekten oluşan yığınların sonuçlarını paralel olarak hesaplamak kolaydır. Ancak iş sinir ağındaki ağırlıkları güncellemeye geldiğinde, mevcut yöntemler bunu temelde parti parti yapmayı gerektiriyor. (Ve evet, bu muhtemelen gerçek beyinlerin - birleşik hesaplama ve bellek unsurlarıyla - şimdilik en azından mimari bir avantaja sahip olduğu yerdir).
Daha önce tartıştığımız sayısal fonksiyonları öğrenme gibi basit görünen durumlarda bile, en azından sıfırdan bir ağı başarılı bir şekilde eğitmek için genellikle milyonlarca örnek kullanmamız gerektiğini gördük. Peki bu, "insan benzeri bir dil" modelini eğitmek için kaç örneğe ihtiyacımız olacağı anlamına geliyor? Bunu bilmenin temel bir "teorik" yolu yok gibi görünüyor. Ancak pratikte ChatGPT birkaç yüz milyar kelime metin üzerinde başarıyla eğitildi.
Metnin bir kısmı birkaç kez, bir kısmı ise yalnızca bir kez beslendi. Ancak bir şekilde gördüğü metinden "ihtiyacı olanı aldı". Ancak öğrenilecek bu hacimde metin göz önüne alındığında, "iyi öğrenmek" için ne kadar büyük bir ağa ihtiyaç duyulmalıdır? Yine, bunu söylemek için henüz temel bir teorik yolumuz yok. Nihayetinde -aşağıda daha ayrıntılı olarak tartışacağımız gibi- insan dilinin ve insanların tipik olarak bu dille söylediklerinin belli bir "toplam algoritmik içeriği" vardır. Ancak bir sonraki soru, bir sinir ağının bu algoritmik içeriğe dayalı bir modeli uygulamada ne kadar verimli olacağıdır. Ve yine bilmiyoruz - ChatGPT'nin başarısı makul ölçüde verimli olduğunu gösterse de.
Sonunda ChatGPT'nin yaptığı işi birkaç yüz milyar ağırlık kullanarak yaptığını not edebiliriz - bu sayı, kendisine verilen eğitim verilerinin toplam kelime (veya jeton) sayısıyla karşılaştırılabilir. Bazı açılardan (ChatGPT'nin daha küçük analoglarında da deneysel olarak gözlemlenmiş olsa da) iyi çalışıyor gibi görünen "ağın boyutunun" "eğitim verisinin boyutuyla" bu kadar karşılaştırılabilir olması şaşırtıcı olabilir. Sonuçta, ChatGPT'nin içinde bir şekilde web'den, kitaplardan vb. gelen tüm metinlerin "doğrudan depolandığı" kesinlikle söylenemez. Çünkü ChatGPT'nin içinde aslında 10 basamaktan biraz daha az hassasiyete sahip bir grup sayı vardır ve bunlar tüm bu metnin toplam yapısının bir tür dağıtılmış kodlamasıdır.
Başka bir deyişle, insan dilinin "etkili bilgi içeriğinin" ne olduğunu ve tipik olarak onunla ne söylendiğini sorabiliriz. Dil örneklerinden oluşan ham bir külliyat vardır. Bir de ChatGPT'nin sinir ağındaki temsili var. Bu temsil büyük olasılıkla "algoritmik olarak minimal" temsilden çok uzaktır (aşağıda tartışacağımız gibi). Ancak sinir ağı tarafından kolayca kullanılabilen bir temsildir. Ve bu temsilde, sonuçta eğitim verilerinde oldukça az "sıkıştırma" var gibi görünüyor; ortalama olarak, bir kelime eğitim verisinin "bilgi içeriğini" taşımak için bir sinir ağı ağırlığından sadece biraz daha azını alıyor gibi görünüyor.
Metin oluşturmak için ChatGPT'yi çalıştırdığımızda, temelde her ağırlığı bir kez kullanmak zorunda kalıyoruz. Yani n tane ağırlık varsa, yapmamız gereken n tane hesaplama adımı vardır - ancak pratikte bunların çoğu GPU'larda paralel olarak yapılabilir. Ancak bu ağırlıkları ayarlamak için yaklaşık n kelimelik eğitim verisine ihtiyacımız varsa, yukarıda söylediklerimizden, ağın eğitimini yapmak için yaklaşık n2 hesaplama adımına ihtiyacımız olacağı sonucuna varabiliriz - bu nedenle mevcut yöntemlerle milyar dolarlık eğitim çabalarından bahsetmek gerekir.
Temel Eğitimin Ötesinde
ChatGPT'yi eğitmek için harcanan çabanın büyük bir kısmı, web'den, kitaplardan vb. büyük miktarda mevcut metni "göstermekle" geçiyor. Ancak görünüşe göre oldukça önemli olan başka bir kısım daha var.
Kendisine gösterilen orijinal metin külliyatından "ham eğitimini" tamamlar tamamlamaz, ChatGPT'nin içindeki sinir ağı kendi metnini üretmeye, yönlendirmelerden vs. devam etmeye hazırdır. Ancak bundan elde edilen sonuçlar genellikle makul görünse de, özellikle uzun metin parçaları için genellikle insani olmayan şekillerde "sapma" eğilimindedirler. Bu, örneğin metin üzerinde geleneksel istatistikler yaparak kolayca tespit edilebilecek bir şey değildir. Ancak metni okuyan gerçek insanların kolayca fark edebileceği bir şeydir.
ChatGPT'nin oluşturulmasındaki temel fikirlerden biri de web gibi şeyleri "pasif olarak okuduktan" sonra bir adım daha atmaktı: gerçek insanların ChatGPT ile aktif olarak etkileşime girmesini sağlamak, ne ürettiğini görmek ve aslında ona "nasıl iyi bir sohbet robotu olunacağı" konusunda geri bildirim vermek. Peki sinir ağı bu geri bildirimi nasıl kullanabilir? İlk adım, insanların sinir ağından gelen sonuçları değerlendirmesini sağlamaktır. Ancak daha sonra bu derecelendirmeleri tahmin etmeye çalışan başka bir sinir ağı modeli oluşturulur. Ancak şimdi bu tahmin modeli, esasen bir kayıp fonksiyonu gibi orijinal ağ üzerinde çalıştırılabilir, böylece ağın verilen insan geri bildirimi tarafından "ayarlanmasına" izin verilir. Ve uygulamadaki sonuçların, sistemin "insan benzeri" çıktı üretmedeki başarısı üzerinde büyük bir etkisi olduğu görülüyor.
Genel olarak, "başlangıçta eğitilmiş" ağın belirli yönlere faydalı bir şekilde gitmesini sağlamak için bu kadar az "dürtmeye" ihtiyaç duyması ilginçtir. Ağın "yeni bir şey öğrenmiş" gibi davranmasını sağlamak için bir eğitim algoritması çalıştırmak, ağırlıkları ayarlamak vb. gerekeceği düşünülebilir.
Ancak durum böyle değildir. Bunun yerine, ChatGPT'ye temel olarak bir kez bir şey söylemek yeterli görünüyor - verdiğiniz komutun bir parçası olarak - ve sonra metin oluştururken ona söylediklerinizi başarıyla kullanabilir. Ve bir kez daha, bunun işe yaradığı gerçeği, ChatGPT'nin "gerçekten ne yaptığını" ve bunun insan dili ve düşüncesinin yapısıyla nasıl ilişkili olduğunu anlamada önemli bir ipucu olduğunu düşünüyorum.
Bu konuda kesinlikle insana benzer bir şey var: en azından tüm bu ön eğitimi aldıktan sonra ona sadece bir kez bir şey söyleyebilirsiniz ve o da bunu "hatırlayabilir" - en azından bunu kullanarak bir metin parçası oluşturacak kadar "uzun süre". Peki böyle bir durumda neler oluyor? "Ona söyleyebileceğiniz her şey zaten orada bir yerde" olabilir - ve siz sadece onu doğru noktaya yönlendiriyor olabilirsiniz. Ama bu pek akla yatkın görünmüyor. Bunun yerine, daha olası görünen şey, evet, unsurların zaten orada olduğu, ancak ayrıntıların "bu unsurlar arasındaki yörünge" gibi bir şey tarafından tanımlandığı ve ona bir şey söylediğinizde bunu tanıttığınızdır.
Gerçekten de, tıpkı insanlar için olduğu gibi, eğer ona bildiği çerçeveye tamamen uymayan tuhaf ve beklenmedik bir şey söylerseniz, bunu başarılı bir şekilde "entegre" edebilecek gibi görünmüyor. Bunu ancak temelde zaten sahip olduğu çerçevenin üzerine oldukça basit bir şekilde biniyorsa "entegre edebilir".
Ayrıca sinir ağının "algılayabileceği" şeylerin kaçınılmaz olarak "algoritmik sınırları" olduğunu tekrar belirtmekte fayda var. Ona "bu şuna gider" vb. biçiminde "sığ" kurallar söyleyin ve sinir ağı büyük olasılıkla bunları gayet iyi temsil edebilecek ve yeniden üretebilecektir - ve aslında dilden "zaten bildiği" şey ona takip etmesi için anında bir model verecektir. Ancak, potansiyel olarak hesaplama açısından indirgenemez birçok adımı içeren gerçek bir "derin" hesaplama için ona kurallar vermeye çalışın ve bu işe yaramayacaktır. (Her adımda ağında her zaman sadece "ileriye doğru veri beslediğini", yeni belirteçler üretme dışında asla döngü oluşturmadığını unutmayın).
Elbette, ağ belirli "indirgenemez" hesaplamaların cevabını öğrenebilir. Ancak kombinatoryal sayıda olasılık olduğu anda, bu tür bir "tablo arama tarzı" yaklaşım işe yaramayacaktır. Ve evet, tıpkı insanlar gibi sinir ağlarının da "ellerini uzatıp" gerçek hesaplama araçlarını kullanmalarının zamanı gelmiştir. (Ve evet, WolframAlpha ve Wolfram Language benzersiz bir şekilde uygundur, çünkü tıpkı dil modeli sinir ağları gibi "dünyadaki şeyler hakkında konuşmak" için inşa edilmişlerdir).
ChatGPT'nin Gerçekten Çalışmasını Sağlayan Nedir?
İnsan dili -ve onu üretmeye dahil olan düşünme süreçleri- her zaman karmaşıklığın bir tür zirvesini temsil ediyor gibi görünmüştür. Ve gerçekten de "sadece" 100 milyar kadar nörondan (ve belki de 100 trilyon bağlantıdan) oluşan ağlarıyla insan beyninin bundan sorumlu olması biraz dikkat çekici görünmüştür. Belki de, beyinlerde nöron ağlarından daha fazla bir şey olduğu - keşfedilmemiş fiziğin yeni bir katmanı gibi - düşünülebilirdi. Ancak şimdi ChatGPT ile önemli yeni bir bilgiye sahibiz: beyinlerin nöron sayısı kadar bağlantıya sahip saf, yapay bir sinir ağının insan dilini üretme konusunda şaşırtıcı derecede iyi bir iş çıkarabildiğini biliyoruz.
Bu hala büyük ve karmaşık bir sistemdir - şu anda dünyada mevcut olan metin kelimeleri kadar sinir ağı ağırlığına sahiptir. Ancak bir düzeyde, dilin tüm zenginliğinin ve hakkında konuşabileceği şeylerin bu kadar sınırlı bir sisteme sığdırılabileceğine inanmak hala zor görünüyor. Olup bitenlerin bir kısmı, hiç şüphesiz, hesaplama süreçlerinin, altta yatan kurallar basit olsa bile sistemlerin görünürdeki karmaşıklığını büyük ölçüde artırabileceği şeklindeki (ilk olarak kural 30 örneğinde ortaya çıkan) her yerde rastlanan olgunun bir yansımasıdır. Ancak, aslında, yukarıda tartıştığımız gibi, ChatGPT'de kullanılan türden sinir ağları, eğitimlerini daha erişilebilir kılmak amacıyla bu olgunun etkisini ve bununla ilişkili hesaplama indirgenemezliğini kısıtlamak için özel olarak inşa edilme eğilimindedir.
O halde ChatGPT gibi bir şey nasıl oluyor da dil konusunda bu kadar ileri gidebiliyor? Bence temel cevap, dilin temel düzeyde bir şekilde göründüğünden daha basit olmasıdır. Bu da ChatGPT'nin -son derece basit sinir ağı yapısıyla bile- insan dilinin ve arkasındaki düşüncenin "özünü" başarıyla yakalayabildiği anlamına geliyor. Dahası, ChatGPT eğitimi sırasında, dildeki (ve düşünmedeki) bunu mümkün kılan düzenlilikleri bir şekilde "örtük olarak keşfetmiştir".
ChatGPT'nin başarısı, bence, bize bilimin temel ve önemli bir parçasının kanıtını veriyor: keşfedilecek büyük yeni "dil yasaları "nın - ve etkili bir şekilde "düşünce yasaları "nın - olmasını bekleyebileceğimizi gösteriyor. Bir sinir ağı olarak inşa edilen ChatGPT'de bu yasalar en iyi ihtimalle örtüktür. Ancak yasaları bir şekilde açık hale getirebilirsek, ChatGPT'nin yaptığı türden şeyleri çok daha doğrudan, verimli ve şeffaf yollarla yapma potansiyeli var.
Peki, tamam, bu yasalar nasıl olabilir? Nihayetinde bize dilin -ve onunla söylediğimiz şeylerin- nasıl bir araya getirildiğine dair bir tür reçete vermeleri gerekir. Daha sonra "ChatGPT'nin içine bakmanın" bize bu konuda nasıl bazı ipuçları verebileceğini ve hesaplamalı dilin inşasından bildiklerimizin nasıl ileriye dönük bir yol önerdiğini tartışacağız. Ama önce "dil yasaları "na ilişkin uzun zamandır bilinen iki örneği ve bunların ChatGPT'nin işleyişiyle nasıl ilişkili olduğunu tartışalım.
Bunlardan ilki dilin sözdizimidir. Dil, kelimelerin rastgele bir araya gelmesinden ibaret değildir. Bunun yerine, farklı türden kelimelerin nasıl bir araya getirilebileceğine dair (oldukça) kesin gramer kuralları vardır: örneğin İngilizce'de isimlerden önce sıfatlar ve ardından fiiller gelebilir, ancak tipik olarak iki isim yan yana gelemez. Bu tür gramer yapısı (en azından yaklaşık olarak) "ayrıştırma ağaçlarının" nasıl bir araya getirilebileceğini tanımlayan bir dizi kural tarafından yakalanabilir:

ChatGPT bu tür kurallar hakkında açık bir "bilgiye" sahip değildir. Ancak bir şekilde eğitimi sırasında bunları dolaylı olarak "keşfediyor" ve sonra bunları takip etmekte iyi görünüyor. Peki bu nasıl çalışıyor? "Büyük resim" düzeyinde bu net değil. Ancak biraz fikir edinmek için belki de çok daha basit bir örneğe bakmak öğretici olabilir.
Parantezlerin her zaman dengeli olması gerektiğini belirten bir dilbilgisi ile ('ler ve )'ler dizilerinden oluşan bir "dil" düşünün, aşağıdaki gibi bir ayrıştırma ağacı ile temsil edildiği gibi:

Bir sinir ağını "dilbilgisi açısından doğru" parantez dizileri üretecek şekilde eğitebilir miyiz? Sinir ağlarında dizileri ele almanın çeşitli yolları vardır, ancak ChatGPT'nin yaptığı gibi dönüştürücü ağları kullanalım. Ve basit bir dönüştürücü ağ verildiğinde, onu dilbilgisi açısından doğru parantez dizilerini eğitim örnekleri olarak beslemeye başlayabiliriz. Bir incelik (aslında ChatGPT'nin insan dili oluşturmasında da görünen), "içerik belirteçlerimize" (burada "(" ve ")") ek olarak, çıktının daha fazla devam etmemesi gerektiğini (yani ChatGPT için "hikayenin sonuna" ulaşıldığını) belirtmek için oluşturulan bir "Son" belirteci eklememiz gerektiğidir.
Eğer 8 başlı tek bir dikkat bloğu ve 128 uzunluğunda özellik vektörleri olan bir transformatör ağı kurarsak (ChatGPT de 128 uzunluğunda özellik vektörleri kullanır, ancak her biri 96 başlı 96 dikkat bloğuna sahiptir), parantez dili hakkında fazla bir şey öğrenmesini sağlamak mümkün görünmemektedir. Ancak 2 dikkat bloğu ile öğrenme süreci yakınsıyor gibi görünüyor - en azından 10 milyon kadar örnek verildikten sonra (ve transformatör ağlarında yaygın olduğu gibi, daha fazla örnek göstermek performansını düşürüyor gibi görünüyor).
Dolayısıyla, bu ağ ile ChatGPT'nin yaptığının benzerini yapabilir ve bir parantez dizisinde bir sonraki belirtecin ne olması gerektiğine dair olasılıklar isteyebiliriz:

Ve ilk durumda, ağ dizinin burada bitemeyeceğinden "oldukça emin" - ki bu iyi bir şey, çünkü eğer biterse, parantezler dengesiz kalırdı. Ancak ikinci durumda, dizinin burada bitebileceğini "doğru bir şekilde tanıyor", ancak aynı zamanda bir "(" koyarak "yeniden başlamanın" mümkün olduğuna "işaret ediyor", muhtemelen bir ")" takip edecek. Ancak, 400.000 kadar zahmetli bir şekilde eğitilmiş ağırlığıyla bile, bir sonraki belirtecin ")" olma olasılığının %15 olduğunu söylüyor ki bu doğru değil, çünkü bu mutlaka dengesiz bir paranteze yol açacaktır.
Ağa giderek daha uzun ('ler dizileri için en yüksek olasılıklı tamamlamaları sorarsak elde edeceğimiz şey şudur:

Belli bir uzunluğa kadar ağ gayet iyi çalışıyor. Ama sonra başarısız olmaya başlar. Bir sinir ağında (veya genel olarak makine öğreniminde) bunun gibi "kesin" bir durumda görmek oldukça tipik bir şeydir. Bir insanın "bir bakışta çözebileceği" vakaları sinir ağı da çözebilir. Ancak "daha algoritmik" bir şey yapmayı gerektiren durumlar (örneğin kapalı olup olmadıklarını görmek için parantezleri açıkça saymak) sinir ağı bir şekilde güvenilir bir şekilde yapmak için "hesaplama açısından çok sığ" olma eğilimindedir. (Bu arada, mevcut tam ChatGPT bile uzun dizilerdeki parantezleri doğru bir şekilde eşleştirmekte zorlanıyor).
Peki bu ChatGPT ve İngilizce gibi bir dilin sözdizimi gibi şeyler için ne anlama geliyor? Parantez dili "sade" ve çok daha "algoritmik bir hikaye". Ancak İngilizcede, yerel sözcük seçimleri ve diğer ipuçları temelinde dilbilgisel olarak neyin uygun olacağını "tahmin edebilmek" çok daha gerçekçi. Ve evet, sinir ağı bu konuda çok daha iyidir - belki de insanların da kaçırabileceği bazı "biçimsel olarak doğru" durumları kaçırsa bile. Ancak asıl önemli nokta, dilin genel bir sözdizimsel yapısı olduğu gerçeğinin - bunun ima ettiği tüm düzenlilikle birlikte - bir anlamda sinir ağının "ne kadar" öğrenmesi gerektiğini sınırlamasıdır. Ve önemli bir "doğa bilimi benzeri" gözlem, ChatGPT'deki gibi sinir ağlarının dönüştürücü mimarisinin, tüm insan dillerinde (en azından yaklaşık olarak) var gibi görünen iç içe geçmiş ağaç benzeri sözdizimsel yapı türünü başarılı bir şekilde öğrenebildiğidir.
Sözdizimi dil üzerinde bir tür kısıtlama sağlar. Ancak açıkça daha fazlası da vardır. "Meraklı elektronlar balık için mavi teorileri yerler" gibi bir cümle dilbilgisi açısından doğrudur, ancak normalde söylenmesi beklenen bir şey değildir ve ChatGPT bunu üretseydi başarılı sayılmazdı - çünkü, içindeki kelimelerin normal anlamlarıyla, temelde anlamsızdır.
Peki bir cümlenin anlamlı olup olmadığını anlamanın genel bir yolu var mı? Bunun için geleneksel bir genel teori yok. Ancak ChatGPT'nin web'den milyarlarca (muhtemelen anlamlı) cümle ile eğitildikten sonra dolaylı olarak "bir teori geliştirdiği" düşünülebilir.
Bu teori neye benziyor olabilir? Temelde iki bin yıldır bilinen küçük bir köşe var, o da mantık. Ve kesinlikle Aristoteles'in keşfettiği kıyas formunda mantık, temelde belirli kalıpları takip eden cümlelerin makul olduğunu, diğerlerinin ise makul olmadığını söylemenin bir yoludur. Dolayısıyla, örneğin, "Tüm X'ler Y'dir. Bu Y değildir, o halde X değildir" demek mantıklıdır ("Tüm balıklar mavidir. Bu mavi değildir, o halde balık değildir" gibi). Ve nasıl ki Aristoteles'in çok sayıda retorik örneğini inceleyerek ("makine öğrenimi tarzı") kıyas mantığını keşfettiğini biraz tuhaf bir şekilde hayal edebiliyorsak, ChatGPT'nin eğitiminde de web'deki çok sayıda metne bakarak "kıyas mantığını keşfedebileceğini" hayal edebiliriz. (Bu nedenle ChatGPT'nin kıyas mantığı gibi şeylere dayalı "doğru çıkarımlar" içeren metinler üretmesi beklenebilirken, daha sofistike biçimsel mantık söz konusu olduğunda durum oldukça farklıdır ve bence burada da parantez eşleştirmede başarısız olduğu aynı tür nedenlerden dolayı başarısız olması beklenebilir).
Dar mantık örneğinin ötesinde, makul derecede anlamlı bir metnin bile sistematik olarak nasıl oluşturulacağı (veya tanınacağı) hakkında ne söylenebilir? Mad Libs gibi çok spesifik "ifade şablonları" kullanan şeyler var. Ancak bir şekilde ChatGPT'nin bunu yapmanın çok daha genel bir yolu var. Ve belki de bunun nasıl yapılabileceği hakkında "175 milyar sinir ağı ağırlığınız olduğunda bir şekilde oluyor" dışında söylenecek bir şey yok. Ancak çok daha basit ve güçlü bir hikaye olduğundan kuvvetle şüpheleniyorum.
Anlam Alanı ve Anlamsal Hareket Yasaları
Yukarıda, ChatGPT içinde herhangi bir metin parçasının, bir tür "dilsel özellik uzayı "ndaki bir noktanın koordinatları olarak düşünebileceğimiz bir dizi sayı ile etkili bir şekilde temsil edildiğini tartıştık. Dolayısıyla ChatGPT bir metin parçasına devam ettiğinde bu, dilbilimsel özellik uzayında bir yörünge izlemeye karşılık gelir. Ancak şimdi bu yörüngenin anlamlı olduğunu düşündüğümüz metne karşılık gelmesini sağlayan şeyin ne olduğunu sorabiliriz. Ve belki de dilsel özellik uzayında noktaların "anlamlılığı" koruyarak nasıl hareket edebileceğini tanımlayan -ya da en azından kısıtlayan- bir tür "anlamsal hareket yasaları" olabilir mi?
Peki bu dilsel özellik uzayı neye benziyor? İşte böyle bir özellik uzayını 2 boyutlu olarak yansıttığımızda tek kelimelerin (burada yaygın isimler) nasıl ortaya çıkabileceğine dair bir örnek:

Yukarıda bitki ve hayvanları temsil eden kelimelere dayanan başka bir örnek gördük. Ancak her iki durumda da önemli olan nokta, "anlamsal olarak benzer kelimelerin" yakın yerleştirilmesidir.
Başka bir örnek olarak, konuşmanın farklı bölümlerine karşılık gelen kelimelerin nasıl yerleştirildiği aşağıda gösterilmiştir:

Elbette, belirli bir kelimenin genel olarak sadece "tek bir anlamı" yoktur (ya da konuşmanın sadece bir bölümüne karşılık gelmesi gerekmez). Ve bir kelimeyi içeren cümlelerin özellik uzayında nasıl yerleştiğine bakarak, buradaki "crane" (kuş mu makine mi?) örneğinde olduğu gibi, genellikle farklı anlamlar "ayrıştırılabilir":

En azından bu özellik uzayını "anlamca yakın kelimeleri" bu uzaya yakın yerleştirmek olarak düşünebiliriz. Ancak bu uzayda ne tür bir ek yapı tanımlayabiliriz? Örneğin, uzaydaki "düzlüğü" yansıtacak bir tür "paralel taşıma" kavramı var mı? Bunu anlamanın bir yolu analojilere bakmaktır:

İki boyuta yansıttığımızda bile, kesinlikle evrensel olarak görülmese de, genellikle en azından bir "düzlük ipucu" vardır.
Peki ya yörüngeler? ChatGPT için bir komut isteminin özellik uzayında izlediği yörüngeye bakabilir ve ardından ChatGPT'nin bunu nasıl sürdürdüğünü görebiliriz:

Burada kesinlikle "geometrik olarak açık" bir hareket yasası yok. Ve bu hiç de şaşırtıcı değil; bunun çok daha karmaşık bir hikaye olmasını bekliyoruz. Örneğin, bulunacak bir "anlamsal hareket yasası" olsa bile, bunun en doğal olarak ne tür bir gömme (ya da aslında hangi "değişkenler") içinde ifade edileceği açık olmaktan uzaktır.
Yukarıdaki resimde, "yörünge "deki birkaç adımı gösteriyoruz - her adımda ChatGPT'nin en olası olduğunu düşündüğü kelimeyi seçiyoruz ("sıfır sıcaklık" durumu). Ancak belirli bir noktada hangi kelimelerin hangi olasılıklarla "gelebileceğini" de sorabiliriz:


İşte toplam 40 adımlık bir üç boyutlu gösterim:

Bu bir karmaşa gibi görünüyor ve "ChatGPT'nin içeride ne yaptığını" ampirik olarak inceleyerek "matematiksel-fizik benzeri" "anlamsal hareket yasalarını" tanımlamayı bekleyebileceğimiz fikrini özellikle teşvik etmek için hiçbir şey yapmıyor. Ama belki de sadece "yanlış değişkenlere" (ya da yanlış koordinat sistemine) bakıyoruz ve eğer doğru değişkene baksaydık, ChatGPT'nin jeodezikleri takip etmek gibi "matematiksel-fiziksel-basit" bir şey yaptığını hemen görebilirdik. Ancak şu an itibariyle, ChatGPT'nin insan dilinin nasıl "bir araya getirildiği" hakkında "keşfettiği" şeyi "iç davranışından" "deneysel olarak çözmeye" hazır değiliz.
Anlamsal Dilbilgisi ve Hesaplamalı Dilin Gücü
"Anlamlı insan dili" üretmek için ne gerekir? Geçmişte, bunun insan beyninden başka bir şey olamayacağını varsayabilirdik. Ama şimdi bunun ChatGPT'nin sinir ağı tarafından oldukça saygın bir şekilde yapılabileceğini biliyoruz. Yine de, belki de gidebileceğimiz en ileri nokta budur ve daha basit - ya da daha insani anlaşılabilir - hiçbir şey işe yaramayacaktır. Ancak benim güçlü şüphem ChatGPT'nin başarısının önemli bir "bilimsel" gerçeği dolaylı olarak ortaya koyduğu yönünde: anlamlı insan dilinde aslında bildiğimizden çok daha fazla yapı ve basitlik var ve sonuçta böyle bir dilin nasıl bir araya getirilebileceğini açıklayan oldukça basit kurallar bile olabilir.
Yukarıda bahsettiğimiz gibi, sözdizimsel dilbilgisi, insan dilinde konuşmanın farklı bölümleri gibi şeylere karşılık gelen kelimelerin nasıl bir araya getirilebileceğine dair kurallar verir. Ancak anlamla ilgilenmek için daha ileri gitmemiz gerekir. Bunu nasıl yapacağımızın bir yolu da dil için sadece sözdizimsel bir gramer değil, aynı zamanda anlamsal bir gramer de düşünmektir.
Sözdiziminin amaçları doğrultusunda, isimler ve fiiller gibi şeyleri tanımlarız. Ancak anlambilim açısından "daha ince derecelendirmelere" ihtiyacımız vardır. Örneğin, "hareket etme" kavramını ve "konumdan bağımsız olarak kimliğini koruyan" bir "nesne" kavramını tanımlayabiliriz. Bu "anlamsal kavramların" her biri için sonsuz sayıda özel örnek vardır. Ancak anlamsal gramerimizin amaçları doğrultusunda, temelde "nesnelerin" "hareket edebileceğini" söyleyen genel bir tür kurala sahip olacağız. Tüm bunların nasıl işleyebileceği hakkında söylenecek çok şey var (bazılarını daha önce de söyledim). Ancak burada ileriye dönük potansiyel yollardan bazılarına işaret eden birkaç açıklama yapmakla yetineceğim.
Bir cümlenin semantik gramere göre mükemmel bir şekilde tamam olsa bile, bunun pratikte gerçekleştirildiği (hatta gerçekleştirilebileceği) anlamına gelmediğini belirtmek gerekir. "Fil Ay'a gitti" şüphesiz anlamsal gramerimizi "geçecektir", ancak gerçek dünyamızda (en azından henüz) kesinlikle gerçekleştirilmemiştir - kurgusal bir dünya için kesinlikle adil bir oyun olmasına rağmen.
"Anlamsal dilbilgisi" hakkında konuşmaya başladığımızda, kısa süre sonra "Bunun altında ne var?" diye sormaya başlarız. Hangi "dünya modelini" varsayıyor? Sözdizimsel bir dilbilgisi gerçekten de yalnızca sözcüklerden dilin oluşturulmasıyla ilgilidir. Ancak anlamsal bir gramer zorunlu olarak bir tür "dünya modeli" ile ilgilenir - gerçek kelimelerden oluşan dilin üzerine katmanlanabileceği bir "iskelet" görevi gören bir şey.
Yakın zamana kadar, (insan) dilinin "dünya modelimizi" tanımlamanın tek genel yolu olduğunu düşünmüş olabiliriz. Zaten birkaç yüzyıl önce, özellikle matematiğe dayalı olarak belirli türden şeylerin biçimlendirilmesi yapılmaya başlandı. Ancak şimdi biçimlendirmeye yönelik çok daha genel bir yaklaşım var: hesaplamalı dil.
Kırk yılı aşkın bir süredir (şu anda Wolfram Dili'nde somutlaştığı şekliyle) benim büyük projem buydu: dünyadaki şeyler ve önem verdiğimiz soyut şeyler hakkında mümkün olduğunca geniş bir şekilde konuşabilen kesin bir sembolik temsil geliştirmek. Örneğin, şehirler, moleküller, görüntüler ve sinir ağları için sembolik temsillerimiz ve bu şeyler hakkında nasıl hesaplama yapılacağına dair yerleşik bilgimiz var.
Onlarca yıllık çalışmanın ardından, bu şekilde pek çok alanı ele aldık. Ancak geçmişte, özellikle "gündelik söylem" ile ilgilenmedik. "İki kilo elma aldım" cümlesinde "iki kilo elmayı" kolayca temsil edebiliriz (ve beslenme ve diğer hesaplamaları yapabiliriz). Ancak (henüz) "satın aldım" için sembolik bir temsilimiz yok.
Bunların hepsi anlamsal dilbilgisi fikriyle ve kavramlar için genel bir sembolik "yapı kitine" sahip olma hedefiyle bağlantılıdır; bu bize neyin neyle bir araya gelebileceğine ve böylece insan diline dönüştürebileceğimiz şeyin "akışına" dair kurallar verecektir.
Ama diyelim ki bu "sembolik söylem diline" sahibiz. Bununla ne yapardık? "Yerel olarak anlamlı metin" üretmek gibi şeyler yapmaya başlayabiliriz. Ama sonuçta muhtemelen daha "küresel olarak anlamlı" sonuçlar isteyeceğiz - bu da dünyada (ya da belki bazı tutarlı kurgusal dünyalarda) gerçekte var olabilecek ya da olabilecek şeyler hakkında daha fazla "hesaplama" anlamına geliyor.
Şu anda Wolfram Language'de pek çok şey hakkında büyük miktarda yerleşik hesaplama bilgisine sahibiz. Ancak tam bir sembolik söylem dili için dünyadaki genel şeyler hakkında ek "hesaplamalar" yapmamız gerekir: bir nesne A'dan B'ye ve B'den C'ye hareket ederse, o zaman A'dan C'ye taşınmıştır, vb.
Sembolik bir söylem dili verildiğinde, bunu "bağımsız ifadeler" yapmak için kullanabiliriz. Ama aynı zamanda "Wolfram-Alpha tarzı" dünya hakkında sorular sormak için de kullanabiliriz. Ya da muhtemelen bazı harici harekete geçirme mekanizmalarıyla "öyle olmasını istediğimiz" şeyleri belirtmek için kullanabiliriz. Ya da belki gerçek dünya hakkında, belki de kurgusal ya da başka türlü düşündüğümüz belirli bir dünya hakkında iddialarda bulunmak için kullanabiliriz.
İnsan dili temelde kesin değildir, çünkü belirli bir hesaplama uygulamasına "bağlı" değildir ve anlamı temelde sadece kullanıcıları arasındaki bir "sosyal sözleşme" ile tanımlanır. Ancak hesaplamalı dil, doğası gereği belirli bir temel kesinliğe sahiptir - çünkü sonuçta belirttiği şey her zaman "bir bilgisayarda açık bir şekilde yürütülebilir". İnsan dili genellikle belli bir belirsizlikten kurtulabilir. ("Gezegen" dediğimizde dış gezegenleri de kapsar mı, kapsamaz mı?) Ancak hesaplama dilinde yaptığımız tüm ayrımlar konusunda kesin ve net olmak zorundayız.
Hesaplama dilinde isimler oluştururken sıradan insan dilinden yararlanmak genellikle uygundur. Ancak hesaplama dilinde sahip oldukları anlamlar mutlaka kesindir ve tipik insan dili kullanımında belirli bir çağrışımı kapsayabilir veya kapsamayabilir.
Genel bir sembolik söylem dili için uygun olan temel "ontoloji" nasıl belirlenmelidir? Bu hiç de kolay değil. Belki de bu yüzden Aristoteles'in iki bin yıldan daha uzun bir süre önce yaptığı ilkel başlangıçlardan bu yana bu konuda çok az şey yapılmıştır. Ancak bugün artık dünyayı hesaplamalı olarak nasıl düşüneceğimiz hakkında çok şey biliyor olmamız gerçekten yardımcı oluyor (ve Fizik Projemizden ve ruliad fikrinden "temel bir metafiziğe" sahip olmanın zararı yok).
Peki tüm bunlar ChatGPT bağlamında ne anlama geliyor? ChatGPT, eğitiminden itibaren anlamsal dilbilgisine karşılık gelen belirli (oldukça etkileyici) bir miktarı etkili bir şekilde "bir araya getirmiştir". Ancak bu başarısı bize hesaplamalı dil formunda daha eksiksiz bir şey inşa etmenin mümkün olacağını düşünmemiz için bir neden veriyor. ChatGPT'nin iç yapısı hakkında şimdiye kadar anladıklarımızın aksine, hesaplamalı dili insanlar tarafından kolayca anlaşılabilecek şekilde tasarlamayı bekleyebiliriz.
Anlamsal dilbilgisi hakkında konuşurken kıyas mantığına bir benzetme yapabiliriz. İlk başlarda kıyas mantığı esasen insan dilinde ifade edilen önermelerle ilgili bir kurallar bütünü idi. Ancak (evet, iki bin yıl sonra) biçimsel mantık geliştirildiğinde, kıyas mantığının orijinal temel yapıları artık örneğin modern dijital devrelerin çalışmasını içeren devasa "biçimsel kuleler" inşa etmek için kullanılabiliyordu. Daha genel anlamsal dilbilgisinin de böyle olmasını bekleyebiliriz. Başlangıçta, sadece metin olarak ifade edilen basit kalıplarla başa çıkabilir. Ancak tüm hesaplamalı dil çerçevesi inşa edildiğinde, tüm muğlaklığıyla insan dili aracılığıyla sadece "zemin kat seviyesi" dışında daha önce hiç erişemediğimiz her türlü şeyle kesin ve resmi bir şekilde çalışmamıza olanak tanıyan yüksek "genelleştirilmiş semantik mantık" kuleleri dikmek için kullanılabileceğini bekleyebiliriz.
Hesaplamalı dilin -ve semantik gramerin- inşasını, şeylerin temsilinde bir tür nihai sıkıştırmayı temsil etmek olarak düşünebiliriz. Çünkü bize, örneğin sıradan insan dilinde var olan tüm "cümle dönüşleri" ile uğraşmadan, mümkün olanın özü hakkında konuşmamızı sağlar. ChatGPT'nin en büyük gücünü de biraz buna benzer bir şey olarak görebiliriz: çünkü o da bir anlamda "delinerek", farklı olası ifade biçimleriyle ilgilenmeden "dili anlamsal olarak anlamlı bir şekilde bir araya getirebileceği" noktaya gelmiştir.
Peki ChatGPT'yi altta yatan hesaplamalı dile uygularsak ne olur? Hesaplamalı dil neyin mümkün olduğunu tanımlayabilir. Ancak yine de eklenebilecek olan şey, örneğin web'deki tüm bu içeriği okumaya dayalı olarak "neyin popüler olduğu" duygusudur. Ancak bu durumda, hesaplama diliyle çalışmak, ChatGPT gibi bir şeyin potansiyel olarak indirgenemez hesaplamalardan yararlanmak için nihai araçlara anında ve temel erişime sahip olduğu anlamına gelir. Bu da onu yalnızca "makul metinler üretebilen" değil, aynı zamanda bu metnin dünya hakkında -ya da hakkında konuştuğu varsayılan her ne ise- gerçekten "doğru" ifadelerde bulunup bulunmadığı konusunda çalışılabilecek her şeyi çözmeyi bekleyebilen bir sistem haline getirir.
ChatGPT Ne Yapıyor ve Neden Çalışıyor?
ChatGPT'nin temel konsepti bir düzeyde oldukça basittir. Web'den, kitaplardan vb. insan tarafından oluşturulmuş büyük bir metin örneğinden başlayın. Ardından bir sinir ağını "bunun gibi" metinler üretmesi için eğitin. Ve özellikle, bir "komut isteminden" başlayabilmesini ve ardından "eğitildiği gibi" bir metinle devam edebilmesini sağlayın.
Gördüğümüz gibi, ChatGPT'deki gerçek sinir ağı çok basit öğelerden oluşuyor - milyarlarca olmasına rağmen. Ve sinir ağının temel işleyişi de çok basittir, esasen şimdiye kadar ürettiği metinden türetilen girdiyi, ürettiği her yeni kelime (veya bir kelimenin bir kısmı) için "öğelerinden bir kez" (herhangi bir döngü vb. olmadan) geçirmekten ibarettir.
Ancak dikkat çekici ve beklenmedik olan şey, bu sürecin web'de, kitaplarda vb. bulunanlara başarılı bir şekilde "benzeyen" bir metin üretebilmesidir. Ve sadece tutarlı bir insan dili olmakla kalmıyor, aynı zamanda "okuduğu" içerikten yararlanarak "komutunu takip eden" "şeyler söylüyor". Her zaman "küresel olarak mantıklı" (ya da doğru hesaplamalara karşılık gelen) şeyler söylemez - çünkü (örneğin WolframAlpha'nın "hesaplama süper güçlerine" erişmeden) sadece eğitim materyalinde "kulağa hoş gelen" şeylere dayanarak "kulağa doğru gelen" şeyler söyler.
ChatGPT'nin özel mühendisliği onu oldukça cazip hale getirmiştir. Ancak nihayetinde (en azından dış araçları kullanana kadar) ChatGPT, biriktirdiği "geleneksel bilgelik istatistikleri "nden "yalnızca" bazı "tutarlı metin dizileri" çıkarıyor. Ancak sonuçların insana bu kadar benzemesi şaşırtıcı. Ve tartıştığım gibi, bu en azından bilimsel olarak çok önemli bir şeye işaret ediyor: insan dilinin (ve arkasındaki düşünce kalıplarının) yapılarında bir şekilde düşündüğümüzden daha basit ve daha "kanun gibi" olduğu. ChatGPT bunu dolaylı olarak keşfetti. Ancak potansiyel olarak semantik gramer, hesaplamalı dil vb. ile bunu açıkça ortaya koyabiliriz.
ChatGPT'nin metin üretirken yaptığı şey çok etkileyici ve sonuçlar genellikle biz insanların üreteceği şeylere çok benziyor. Peki bu ChatGPT'nin bir beyin gibi çalıştığı anlamına mı geliyor? Altta yatan yapay sinir ağı yapısı nihayetinde beynin idealleştirilmesi üzerine modellenmiştir. Ve biz insanlar dil üretirken olup bitenlerin birçok yönünün oldukça benzer olması oldukça muhtemel görünüyor.
Eğitim (diğer adıyla öğrenme) söz konusu olduğunda, beynin ve mevcut bilgisayarların farklı "donanımları" (ve belki de bazı gelişmemiş algoritmik fikirler) ChatGPT'yi muhtemelen beyinden oldukça farklı (ve bazı yönlerden çok daha az verimli) bir strateji kullanmaya zorlamaktadır. Ayrıca başka bir şey daha var: tipik algoritmik hesaplamanın aksine, ChatGPT dahili olarak "döngülere sahip değil" veya "veriler üzerinde yeniden hesaplama" yapmıyor. Bu da kaçınılmaz olarak hesaplama kapasitesini sınırlıyor - mevcut bilgisayarlarla karşılaştırıldığında bile, ama kesinlikle beyinle karşılaştırıldığında.
Bunu nasıl "düzelteceğimiz" ve sistemi makul bir verimlilikle eğitme yeteneğini nasıl koruyacağımız açık değil. Ancak bunu yapmak muhtemelen gelecekteki bir ChatGPT'nin daha da fazla "beyin benzeri şeyler" yapmasına izin verecektir. Elbette beyinlerin çok iyi yapamadığı pek çok şey var - özellikle de indirgenemez hesaplamalarla ilgili olanlar. Ve bunlar için hem beyinlerin hem de ChatGPT gibi şeylerin Wolfram Dili gibi "dış araçlar" araması gerekiyor.
Ancak şimdilik ChatGPT'nin neler yapabildiğini görmek heyecan verici. Bir düzeyde, çok sayıda basit hesaplama öğesinin dikkate değer ve beklenmedik şeyler yapabileceğine dair temel bilimsel gerçeğin harika bir örneği. Ama aynı zamanda, insan dilinin ve arkasındaki düşünme süreçlerinin temel karakterinin ve ilkelerinin ne olabileceğini daha iyi anlamak için belki de iki bin yıldır sahip olduğumuz en iyi itici gücü sağlıyor.
Hiç yorum yok:
Yorum Gönder